1. 网址:http://www.mm131.com
浏览器里点击后,按分类和页数得到新的地址:”http://www.mm131.com/xinggan/list_6_%s.html” % index
(如果清纯:”http://www.mm131.com/qingchun/list_1_%s.html” % index , index:页数)
2. Test_Url.py,双重循化先获取图片人物地址,在获取人物每页的图片
from urllib import request
import re
from bs4 import BeautifulSoup
def get_html(url):
req = request.Request(url)
return request.urlopen(req).read()
if __name__ == __main__:
url = “http://www.mm131.com/xinggan/list_6_2.html”
html = get_html(url)
data = BeautifulSoup(html, “lxml”)
p = r“(http://www\S*/\d{4}\.html)”
get_list = re.findall(p, str(data))
# 循化人物地址
for i in range(20):
# print(get_list[i])
# 循环人物的N页图片
for j in range(200):
url2 = get_list[i][:–5] + “_” + str(j + 2) + “.html”
try:
html2 = get_html(url2)
except:
break
p = r“(http://\S*/\d{4}\S*\.jpg)”
get_list2 = re.findall(p, str(html2))
print(get_list2[0])
break
3. 下载图片 Test_Down.py,用豆瓣下载的方法下载,发现不论下载多少张,都是一样的下面图片
这个就有点尴尬了,妹子图片地址都有了,就是不能下载,浏览器打开的时候也是时好时坏,网上也找不到原因,当然楼主最终还是找到原因了,下面先贴上代码
from urllib import request
import requests
def get_image(url):
req = request.Request(url)
get_img = request.urlopen(req).read()
with open(E:/Python_Doc/Images/DownTest/123.jpg, wb) as fp:
fp.write(get_img)
print(“Download success!”)
return
def get_image2(url_ref, url):
headers = {“Referer”: url_ref,
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36
(KHTML, like Gecko)Chrome/62.0.3202.94 Safari/537.36}
content = requests.get(url, headers=headers)
if content.status_code == 200:
with open(E:/Python_Doc/Images/DownTest/124.jpg, wb) as f:
for chunk in content:
f.write(chunk)
print(“Download success!”)
if __name__ == __main__:
url_ref = “http://www.mm131.com/xinggan/2343_3.html”
url = “http://img1.mm131.me/pic/2343/3.jpg”
get_image2(url_ref, url)
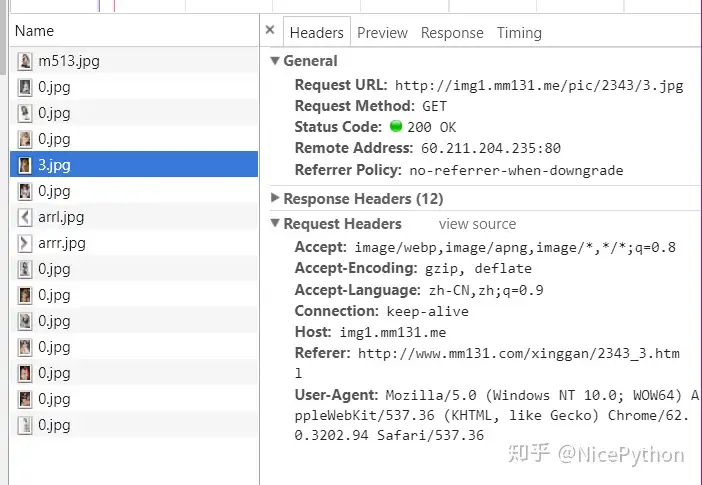
可以看到下载成功,改用requests.get方法获取图片内容,这种请求方法方便设置头文件headers(urllib.request怎么设置headers没有研究过),headers里面有个Referer参数,必须设置为此图片的进入地址,从浏览器F12代码可以看出来,如下图
4. 测试都通过了,下面是汇总的完整源码
from urllib import request
from urllib.request import urlopen
from bs4 import BeautifulSoup
import os
import time
import re
import requests
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
# 全局声明的可以写到配置文件,这里为了读者方便看,故只写在一个文件里面
# 图片地址
picpath = rE:\Python_Doc\Images
# mm131地址
mm_url = “http://www.mm131.com/xinggan/list_6_%s.html”
# 保存路径的文件夹,没有则自己创建文件夹,不能创建上级文件夹
def setpath(name):
path = os.path.join(picpath, name)
if not os.path.isdir(path):
os.mkdir(path)
return path
# 获取html内容
def get_html(url):
req = request.Request(url)
return request.urlopen(req).read()
def save_image2(path, url_ref, url):
headers = {“Referer”: url_ref,
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36
(KHTML, like Gecko)Chrome/62.0.3202.94 Safari/537.36}
content = requests.get(url, headers=headers)
if content.status_code == 200:
with open(path + / + str(time.time()) + .jpg, wb) as f:
for chunk in content:
f.write(chunk)
def do_task(path, url):
html = get_html(url)
data = BeautifulSoup(html, “lxml”)
p = r”(http://www\S*/\d{1,5}\.html)”
get_list = re.findall(p, str(data))
# print(data)
# 循化人物地址 每页20个
for i in range(20):
try:
print(get_list[i])
except:
break
# 循环人物的N页图片
for j in range(200):
url2 = get_list[i][:-5] + “_” + str(3*j + 2) + “.html”
try:
html2 = get_html(url2)
except:
break
p = r”(http://\S*/\d{1,4}\S*\.jpg)”
get_list2 = re.findall(p, str(html2))
save_image2(path, get_list[i], get_list2[0])
if __name__ == __main__:
# 文件名
filename = “MM131_XG”
filepath = setpath(filename)
for i in range(2, 100):
print(“正在List_6_%s ” % i)
url = mm_url % i
do_task(filepath, url)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END