本文参考:
Github – go-ethereum-code-analysisEthereum 黄皮书形式化定义参考Ethereum wiki – RLP
定义
根据以太坊的wiki定义
RLP (递归长度前缀)提供了一种适用于任意二进制数据数组的编码,RLP已经成为以太坊中对对象进行序列化的主要编码方式。 RLP的唯一目标就是解决结构体的编码问题;对原子数据类型(比如,字符串,整数型,浮点型)的编码则交给更高层的协议;以太坊中要求数字必须是一个大端字节序的、没有零占位的存储的格式(也就是说,一个整数0和一个空数组是等同的)。
RLP 编码函数接受一个item。定义如下:
将一个字符串作为一个item(比如,一个 byte 数组)一组item列表(list)作为一个item
例如,一个空字符串可以是一个item,一个字符串”cat”也可以是一个item,一个含有多个字符串的列表也行,复杂的数据结构也行,比如这样的[“cat”,[“puppy”,”cow”],”horse”,[[]],”pig”,[””],”sheep”]。注意在本文后续内容中,说”字符串”的意思其实就相当于”一个确定长度的二进制字节信息数据”;而不要假设或考虑关于字符的编码问题。
RLP 编码定义如下:(黄皮书的形式化定义)
对于 [0x00, 0x7f] 范围内的单个字节, RLP 编码内容就是字节内容本身。否则,如果是一个 0-55 字节长的字符串,则RLP编码有一个特别的数值 0x80 加上字符串长度,再加上字符串二进制内容。这样,第一个字节的表达范围为 [0x80, 0xb7].如果字符串长度超过 55 个字节,RLP 编码由定值 0xb7 加上字符串长度所占用的字节数,加上字符串长度的编码,加上字符串二进制内容组成。比如,一个长度为 1024 的字符串,将被编码为\xb9\x04\x00 后面再加上字符串内容。第一字节的表达范围是[0xb8, 0xbf]。如果列表的内容(它的所有项的组合长度)是0-55个字节长,它的RLP编码由0xC0加上所有的项的RLP编码串联起来的长度得到的单个字节,后跟所有的项的RLP编码的串联组成。 第一字节的范围因此是[0xc0, 0xf7]如果列表的内容超过55字节,它的RLP编码由0xC0加上所有的项的RLP编码串联起来的长度的长度得到的单个字节,后跟所有的项的RLP编码串联起来的长度的长度,再后跟所有的项的RLP编码的串联组成。 第一字节的范围因此是[0xf8, 0xff] 。
RLP把所有的数据看成两类数据的组合, 一类是字节数组, 一类是类似于List的数据结构。 我理解这两类基本包含了所有的数据结构。 比如用得比较多的struct。 可以看成是一个很多不同类型的字段组成的List
例子
字符串 “dog” = [ 0x83, ‘d’, ‘o’, ‘g’ ]
列表 [ “cat”, “dog” ] = [ 0xc8, 0x83, ‘c’, ‘a’, ‘t’, 0x83, ‘d’, ‘o’, ‘g’ ]
空字符串 (‘null’) = [ 0x80 ]
空列表 = [ 0xc0 ]
数字15 (‘\x0f’) = [ 0x0f ]
数字 1024 (‘\x04\x00’) = [ 0x82, 0x04, 0x00 ]
The set theoretical representation of two, [ [], [[]], [ [], [[]] ] ] = [ 0xc7, 0xc0, 0xc1, 0xc0, 0xc3, 0xc0, 0xc1, 0xc0 ]
字符串 “Lorem ipsum dolor sit amet, consectetur adipisicing elit” = [ 0xb8, 0x38, ‘L’, ‘o’, ‘r’, ‘e’, ‘m’, ‘ ‘, … , ‘e’, ‘l’, ‘i’, ‘t’ ]
RLP源码分析
decode.go 解码器,把RLP数据解码为go的数据结构
decode_tail_test.go 解码器测试代码
decode_test.go 解码器测试代码
doc.go 文档代码
encode.go 编码器,把GO的数据结构序列化为字节数组
encode_test.go 编码器测试
encode_example_test.go
raw.go 未解码的RLP数据
raw_test.go
typecache.go 类型缓存, 类型缓存记录了类型->(编码器|解码器)的内容。
typecache
我们知道RLP模块需要对ethereum内所有的对象进行编码,对于不同类型的数据得用不同的函数进行处理,但是golang不支持类似C++/JAVA那样的重载,所以函数的分派得自己实现。typecache.go主要是实现这个目的, 通过自身的类型来快速的找到自己的编码器函数和解码器函数。
// go-ethereum/rlp/typecache.go
var (
typeCacheMutex sync.RWMutex //读写锁,用来在多线程的时候保护typeCache这个Map
typeCache = make(map[typekey]*typeinfo) //核心数据结构,保存了类型->编解码器函数
)
type typeinfo struct { //存储了编码器和解码器函数
decoder
writer
}
type typekey struct {
reflect.Type
// the key must include the struct tags because they
// might generate a different decoder.
tags
}
我们可以看出typeCache是一个全局变量,很多线程会同时调用,所以需要读写锁来保护数据的一致性。每个typekey都有自己的typeinfo,而typeinfo中包含解码器(decoder)和编码器(writer)。从而实现对不同种类数据的编码。
下面的代码是产生typeinfo(writer和decoder)的源码
// go-ethereum/rlp/typecache.go
//用户获取编码器和解码器的函数
func cachedTypeInfo(typ reflect.Type, tags tags) (*typeinfo, error) {
typeCacheMutex.RLock() //加读锁来保护,
info := typeCache[typekey{typ, tags}]
typeCacheMutex.RUnlock()
if info != nil { //如果成功获取到信息,那么就返回
return info, nil
}
// not in the cache, need to generate info for this type.
typeCacheMutex.Lock()
//否则加写锁 调用cachedTypeInfo1函数创建并返回, 这里需要注意的是在多线程环境下有可能多个线程同时调用到这个地方,
//所以当你进入cachedTypeInfo1方法的时候需要判断一下是否已经被别的线程先创建成功了。
defer typeCacheMutex.Unlock()
return cachedTypeInfo1(typ, tags)
}
func cachedTypeInfo1(typ reflect.Type, tags tags) (*typeinfo, error) {
key := typekey{typ, tags}
info := typeCache[key]
if info != nil {
// another goroutine got the write lock first
// 其他的线程可能已经创建成功了, 那么我们直接获取到信息然后返回
return info, nil
}
// put a dummy value into the cache before generating.
// if the generator tries to lookup itself, it will get
// the dummy value and wont call itself recursively.
//这个地方首先创建了一个值来填充这个类型的位置,避免遇到一些递归定义的数据类型形成死循环
typeCache[key] = new(typeinfo)
info, err := genTypeInfo(typ, tags)
if err != nil {
// remove the dummy value if the generator fails
delete(typeCache, key)
return nil, err
}
*typeCache[key] = *info
return typeCache[key], err
}
cachedTypeInfo如果能找到对应typekey的typeinfo的话,就直接返回,如果没找到就进入cachedTypeInfo1中,调用genTypeInfo去产生一个新的typeinfo(包含编码/解码器)。
// go-ethereum/rlp/typecache.go
func genTypeInfo(typ reflect.Type, tags tags) (info *typeinfo, err error) {
info = new(typeinfo)
if info.decoder, err = makeDecoder(typ, tags); err != nil {
return nil, err
}
if info.writer, err = makeWriter(typ, tags); err != nil {
return nil, err
}
return info, nil
}
makeDecoder的处理逻辑和makeWriter的处理逻辑大致差不多, 这里我就只贴出makeWriter的处理逻辑,
// go-ethereum/rlp/encode.go
// makeWriter creates a writer function for the given type.
func makeWriter(typ reflect.Type, ts tags) (writer, error) {
kind := typ.Kind()
switch {
case typ == rawValueType:
return writeRawValue, nil
case typ.Implements(encoderInterface):
return writeEncoder, nil
case kind != reflect.Ptr && reflect.PtrTo(typ).Implements(encoderInterface):
return writeEncoderNoPtr, nil
case kind == reflect.Interface:
return writeInterface, nil
case typ.AssignableTo(reflect.PtrTo(bigInt)):
return writeBigIntPtr, nil
case typ.AssignableTo(bigInt):
return writeBigIntNoPtr, nil
case isUint(kind):
return writeUint, nil
case kind == reflect.Bool:
return writeBool, nil
case kind == reflect.String:
return writeString, nil
case kind == reflect.Slice && isByte(typ.Elem()):
return writeBytes, nil
case kind == reflect.Array && isByte(typ.Elem()):
return writeByteArray, nil
case kind == reflect.Slice || kind == reflect.Array:
return makeSliceWriter(typ, ts)
case kind == reflect.Struct:
return makeStructWriter(typ)
case kind == reflect.Ptr:
return makePtrWriter(typ)
default:
return nil, fmt.Errorf(“rlp: type %v is not RLP-serializable”, typ)
}
}
可以看到就是一个switch case,根据类型来分配不同的处理函数。 这个处理逻辑还是很简单的。针对简单类型很简单,根据黄皮书上面的描述来处理即可。
比如writeUint,这里的处理过程和我们之前对RLP编码的描述是一致的。
// go-ethereum/rlp/encode.go
func writeUint(val reflect.Value, w *encbuf) error {
i := val.Uint()
if i == 0 {
w.str = append(w.str, 0x80)
} else if i < 128 {
// fits single byte
w.str = append(w.str, byte(i))
} else {
// TODO: encode int to w.str directly
s := putint(w.sizebuf[1:], i)
w.sizebuf[0] = 0x80 + byte(s)
w.str = append(w.str, w.sizebuf[:s+1]…)
}
return nil
}
不过,下方函数对于结构体类型的处理还是挺有意思的,而且这部分详细的处理逻辑在黄皮书上面也是找不到的。
// go-ethereum/rlp/encode.go
func makeStructWriter(typ reflect.Type) (writer, error) {
// 把结构体扁平化生一个fields数组,每个元素都有对应的编码器
fields, err := structFields(typ)
if err != nil {
return nil, err
}
writer := func(val reflect.Value, w *encbuf) error {
lh := w.list()
for _, f := range fields {
//f是field结构, f.info是typeinfo的指针, 所以这里其实是调用字段的编码器方法。
if err := f.info.writer(val.Field(f.index), w); err != nil {
return err
}
}
w.listEnd(lh)
return nil
}
return writer, nil
}
这个函数定义了结构体的编码方式, 通过structFields方法得到了所有的字段的编码器, 然后返回一个方法,这个方法遍历所有的字段,每个字段调用其编码器方法。结构体的成员用index来对应(reflect的功能)。
// go-ethereum/rlp/typecache.go
type field struct {
index int
info *typeinfo
}
//这个函数定义了结构体的编码方式, 通过structFields方法得到了所有的字段的编码器,
//然后返回一个方法,这个方法遍历所有的字段,每个字段调用其编码器方法。
func structFields(typ reflect.Type) (fields []field, err error) {
for i := 0; i < typ.NumField(); i++ {
if f := typ.Field(i); f.PkgPath == “” { // exported
tags, err := parseStructTag(typ, i)
if err != nil {
return nil, err
}
if tags.ignored {
continue
}
// 还是回到了cachedTypeInfo1函数,它为每一个field产生对应的typeinfo
info, err := cachedTypeInfo1(f.Type, tags)
if err != nil {
return nil, err
}
fields = append(fields, field{i, info})
}
}
return fields, nil
}
编码器 encode.go
首先定义了空字符串和空List的值,分别是 0x80和0xC0。 注意,整形的0值的对应值也是0x80。这个在黄皮书上面是没有看到有定义的。 然后定义了一个接口类型给别的类型实现 EncodeRLP
// go-ethereum/rlp/encode.go
var (
// Common encoded values.
// These are useful when implementing EncodeRLP.
EmptyString = []byte{0x80}
EmptyList = []byte{0xC0}
)
// Encoder is implemented by types that require custom
// encoding rules or want to encode private fields.
type Encoder interface {
// EncodeRLP should write the RLP encoding of its receiver to w.
// If the implementation is a pointer method, it may also be
// called for nil pointers.
//
// Implementations should generate valid RLP. The data written is
// not verified at the moment, but a future version might. It is
// recommended to write only a single value but writing multiple
// values or no value at all is also permitted.
EncodeRLP(io.Writer) error
}
…
func writeEncoder(val reflect.Value, w *encbuf) error {
return val.Interface().(Encoder).EncodeRLP(w)
}
大部分的EncodeRLP方法都是直接调用了rlp.Encode方法。我们来举个例子,下面这个函数在p2p/enr/entries.go中,这是用于对IP进行RLP编码的函数。她最终通过调用rlp.Encode方法来对IP进行编码
// go-ethereum/p2p/enr/entries.go
// EncodeRLP implements rlp.Encoder.
func (v IP) EncodeRLP(w io.Writer) error {
if ip4 := net.IP(v).To4(); ip4 != nil {
return rlp.Encode(w, ip4)
}
return rlp.Encode(w, net.IP(v))
}
接下来我们看看rlp.Encode这个方法。这个方法首先取得一个encbuf对象。(如果取不到就从sync pool中拿出一个encbuf来使用) 然后调用这个对象的encode方法。encode方法中,首先获取了对象的反射类型,根据反射类型获取它的编码器,然后调用编码器的writer方法。这个就跟上面谈到的typecache联系到一起了。
// go-ethereum/rlp/encode.go
// encbufs are pooled.
var encbufPool = sync.Pool{
New: func() interface{} { return &encbuf{sizebuf: make([]byte, 9)} },
}
…
func Encode(w io.Writer, val interface{}) error {
//判断w是否为*encbuf类型
if outer, ok := w.(*encbuf); ok {
// Encode was called by some types EncodeRLP.
// Avoid copying by writing to the outer encbuf directly.
return outer.encode(val)
}
// 从sync Pool中拿出一个encbuf使用
eb := encbufPool.Get().(*encbuf)
defer encbufPool.Put(eb)
// 在把enchuf放回去之前,reset一下为了后面使用
eb.reset()
if err := eb.encode(val); err != nil {
return err
}
return eb.toWriter(w)
}
…
// 用对应的编码器把val的值编码后写入encbuf里面
func (w *encbuf) encode(val interface{}) error {
rval := reflect.ValueOf(val)
ti, err := cachedTypeInfo(rval.Type(), tags{})
if err != nil {
return err
}
return ti.writer(rval, w)
}
encbuf
这个是在encode的过程中充当buffer的作用。下面先看看encbuf的定义。
// go-ethereum/rlp/encode.go
type encbuf struct {
str []byte // string data, contains everything except list headers
lheads []*listhead // all list headers
lhsize int // sum of sizes of all encoded list headers
sizebuf []byte // 9-byte auxiliary buffer for uint encoding
}
type listhead struct {
offset int // index of this header in string data
size int // total size of encoded data (including list headers)
}
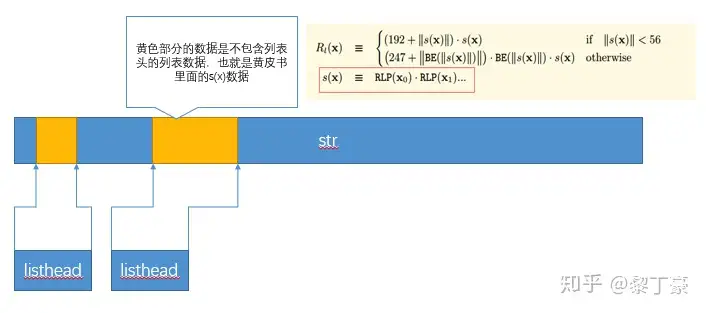
从注释可以看到, str字段包含了所有的内容,除了列表的头部。列表的头部记录在lheads字段中。lhsize字段记录了lheads的长度,sizebuf是9个字节大小的辅助buffer,专门用来处理uint的编码的。listhead由两个字段组成,offset字段记录了列表数据在str字段的哪个位置,size字段记录了包含列表头的编码后的数据的总长度。可以看到下面的图。
对于普通的类型,比如字符串,整形,bool型等数据,就是直接往str字段里面填充就行了。但是对于结构体类型的处理,就需要特殊的处理方式了。可以看看上面提到过的makeStructWriter方法。
// go-ethereum/rlp/encode.go
func makeStructWriter(typ reflect.Type) (writer, error) {
// 把结构体扁平化生一个fields数组,每个元素都有对应的编码器
fields, err := structFields(typ)
if err != nil {
return nil, err
}
writer := func(val reflect.Value, w *encbuf) error {
lh := w.list()
for _, f := range fields {
//f是field结构, f.info是typeinfo的指针, 所以这里其实是调用字段的编码器方法。
if err := f.info.writer(val.Field(f.index), w); err != nil {
return err
}
}
w.listEnd(lh)
return nil
}
return writer, nil
}
…
func (w *encbuf) list() *listhead {
//记录当前的w.str大小和w.lhsize的大小
lh := &listhead{offset: len(w.str), size: w.lhsize}
w.lheads = append(w.lheads, lh)
return lh
}
func (w *encbuf) listEnd(lh *listhead) {
// 获取str最新增加的数据的多少来决定头的处理方式
lh.size = w.size() – lh.offset – lh.size
if lh.size < 56 {
w.lhsize++ // length encoded into kind tag
} else {
w.lhsize += 1 + intsize(uint64(lh.size))
}
}
func (w *encbuf) size() int {
return len(w.str) + w.lhsize
}
可以看到上面的代码中体现了处理结构体数据的特殊处理方法,就是首先调用w.list()方法,处理完毕之后再调用listEnd(lh)方法。采用这种方式的原因是我们在刚开始处理结构体的时候,并不知道处理后的结构体的长度有多长,因为需要根据结构体的长度来决定头的处理方式(回忆一下黄皮书里面结构体的处理方式),所以我们在处理前记录好str的位置,然后开始处理每个字段,处理完之后在看一下str的数据增加了多少就知道处理后的结构体长度有多长了。
最后,我们可以看看encbuf最后的处理逻辑,会对listhead进行处理,组装成完整的RLP数据
// go-ethereum/rlp/encode.go
// EncodeToBytes returns the RLP encoding of val.
// Please see the documentation of Encode for the encoding rules.
func EncodeToBytes(val interface{}) ([]byte, error) {
eb := encbufPool.Get().(*encbuf)
defer encbufPool.Put(eb)
eb.reset()
if err := eb.encode(val); err != nil {
return nil, err
}
return eb.toBytes(), nil
}
func (w *encbuf) encode(val interface{}) error {
rval := reflect.ValueOf(val)
ti, err := cachedTypeInfo(rval.Type(), tags{})
if err != nil {
return err
}
return ti.writer(rval, w)
}
各种writer
在之前讲makeWriter的时候,我们说过,我们用type来选择writer,而不同的writer就是根据黄皮书针把每种不同的数据填充到encbuf里面去
// go-ethereum/rlp/encode.go
func writeBool(val reflect.Value, w *encbuf) error {
if val.Bool() {
w.str = append(w.str, 0x01)
} else {
w.str = append(w.str, 0x80)
}
return nil
}
func writeBigIntPtr(val reflect.Value, w *encbuf) error {
ptr := val.Interface().(*big.Int)
if ptr == nil {
w.str = append(w.str, 0x80)
return nil
}
return writeBigInt(ptr, w)
}
解码器decode.go
解码器的大致流程和编码器差不多,理解了编码器的大致流程,也就知道了解码器的大致流程。
// go-ethereum/rlp/decode.go
func makeDecoder(typ reflect.Type, tags tags) (dec decoder, err error) {
kind := typ.Kind()
switch {
case typ == rawValueType:
return decodeRawValue, nil
case typ.Implements(decoderInterface):
return decodeDecoder, nil
case kind != reflect.Ptr && reflect.PtrTo(typ).Implements(decoderInterface):
return decodeDecoderNoPtr, nil
case typ.AssignableTo(reflect.PtrTo(bigInt)):
return decodeBigInt, nil
case typ.AssignableTo(bigInt):
return decodeBigIntNoPtr, nil
case isUint(kind):
return decodeUint, nil
case kind == reflect.Bool:
return decodeBool, nil
case kind == reflect.String:
return decodeString, nil
case kind == reflect.Slice || kind == reflect.Array:
return makeListDecoder(typ, tags)
case kind == reflect.Struct:
return makeStructDecoder(typ)
case kind == reflect.Ptr:
if tags.nilOK {
return makeOptionalPtrDecoder(typ)
}
return makePtrDecoder(typ)
case kind == reflect.Interface:
return decodeInterface, nil
default:
return nil, fmt.Errorf(“rlp: type %v is not RLP-serializable”, typ)
}
}
…
// Decode decodes a value and stores the result in the value pointed
// to by val. Please see the documentation for the Decode function
// to learn about the decoding rules.
func (s *Stream) Decode(val interface{}) error {
if val == nil {
return errDecodeIntoNil
}
rval := reflect.ValueOf(val)
rtyp := rval.Type()
if rtyp.Kind() != reflect.Ptr {
return errNoPointer
}
if rval.IsNil() {
return errDecodeIntoNil
}
info, err := cachedTypeInfo(rtyp.Elem(), tags{})
if err != nil {
return err
}
err = info.decoder(s, rval.Elem())
if decErr, ok := err.(*decodeError); ok && len(decErr.ctx) > 0 {
// add decode target type to error so context has more meaning
decErr.ctx = append(decErr.ctx, fmt.Sprint(“(“, rtyp.Elem(), “)”))
}
return err
}
我们同样通过结构体类型的解码过程来查看具体的解码过程。跟编码过程差不多,首先通过structFields获取需要解码的所有字段,然后每个字段进行解码。跟编码过程差不多有一个List()和ListEnd()的操作,不过这里的处理流程和编码过程不一样,后续章节会详细介绍。
// go-ethereum/rlp/decode.go
func makeStructDecoder(typ reflect.Type) (decoder, error) {
// 把结构体变为数组,使之扁平化,
// feilds是”fields”类型的数组,每个元素都包含一个index和一个typeinfo
fields, err := structFields(typ)
if err != nil {
return nil, err
}
//这里使对fields用了闭包的特性
dec := func(s *Stream, val reflect.Value) (err error) {
// 记录了当前这个list已经读取了多少字节的数据
if _, err := s.List(); err != nil {
return wrapStreamError(err, typ)
}
for _, f := range fields {
//f是field结构, f.info是typeinfo的指针, 所以这里其实是调用字段的编码器方法。
//根据不同field调用相应的解码器
err := f.info.decoder(s, val.Field(f.index))
if err == EOL {
return &decodeError{msg: “too few elements”, typ: typ}
} else if err != nil {
return addErrorContext(err, “.”+typ.Field(f.index).Name)
}
}
return wrapStreamError(s.ListEnd(), typ)
}
return dec, nil
}
下面在看字符串的解码过程,因为不同长度的字符串有不同方式的编码,我们可以通过前缀的不同来获取字符串的类型,这里我们通过s.Kind()方法获取当前需要解析的类型和长度,如果是Byte类型,那么直接返回Byte的值, 如果是String类型那么读取指定长度的值然后返回。 这就是kind()方法的用途。
// go-ethereum/rlp/decode.go
// Bytes reads an RLP string and returns its contents as a byte slice.
// If the input does not contain an RLP string, the returned
// error will be ErrExpectedString.
func (s *Stream) Bytes() ([]byte, error) {
kind, size, err := s.Kind()
if err != nil {
return nil, err
}
switch kind {
case Byte:
s.kind = –1 // rearm Kind
return []byte{s.byteval}, nil
case String:
b := make([]byte, size)
if err = s.readFull(b); err != nil {
return nil, err
}
if size == 1 && b[0] < 128 {
return nil, ErrCanonSize
}
return b, nil
default:
return nil, ErrExpectedString
}
}
…
// Kind returns the kind and size of the next value in the
// input stream.
//
// The returned size is the number of bytes that make up the value.
// For kind == Byte, the size is zero because the value is
// contained in the type tag.
//
// The first call to Kind will read size information from the input
// reader and leave it positioned at the start of the actual bytes of
// the value. Subsequent calls to Kind (until the value is decoded)
// will not advance the input reader and return cached information.
func (s *Stream) Kind() (kind Kind, size uint64, err error) {
var tos *listpos
if len(s.stack) > 0 {
tos = &s.stack[len(s.stack)–1]
}
if s.kind < 0 {
s.kinderr = nil
// Dont read further if were at the end of the
// innermost list.
if tos != nil && tos.pos == tos.size {
return 0, 0, EOL
}
s.kind, s.size, s.kinderr = s.readKind()
if s.kinderr == nil {
if tos == nil {
// At toplevel, check that the value is smaller
// than the remaining input length.
if s.limited && s.size > s.remaining {
s.kinderr = ErrValueTooLarge
}
} else {
// Inside a list, check that the value doesnt overflow the list.
if s.size > tos.size–tos.pos {
s.kinderr = ErrElemTooLarge
}
}
}
}
// Note: this might return a sticky error generated
// by an earlier call to readKind.
return s.kind, s.size, s.kinderr
}
Stream 结构分析
解码器的其他代码和编码器的结构差不多, 但是有一个特殊的结构是编码器里面没有的。那就是Stream。 这个是用来读取用流式的方式来解码RLP的一个辅助类。
前面我们讲到了大致的解码流程就是首先通过Kind()方法获取需要解码的对象的类型和长度,然后根据长度和类型进行数据的解码。那么我们如何处理结构体的字段又是结构体的数据呢,回忆我们对结构体进行处理的时候,首先调用s.List()方法,然后对每个字段进行解码,最后调用s.EndList()方法。 技巧就在这两个方法里面,下面我们看看这两个方法。
// go-ethereum/rlp/decode.go
type Stream struct {
r ByteReader
// number of bytes remaining to be read from r.
remaining uint64
limited bool
// auxiliary buffer for integer decoding
uintbuf []byte
kind Kind // kind of value ahead
size uint64 // size of value ahead
byteval byte // value of single byte in type tag
kinderr error // error from last readKind
stack []listpos
}
type listpos struct{ pos, size uint64 }Stream的List方法,当调用List方法的时候。我们先调用Kind方法获取类型和长度,如果类型不匹配那么就抛出错误,然后我们把一个listpos对象压入到堆栈,这个对象是关键。 这个对象的pos字段记录了当前这个list已经读取了多少字节的数据, 所以刚开始的时候肯定是0。 size字段记录了这个list对象一共需要读取多少字节数据。这样我在处理后续的每一个字段的时候,每读取一些字节,就会增加pos这个字段的值,处理到最后会对比pos字段和size字段是否相等,如果不相等,那么会抛出异常。
Stream的ListEnd方法,如果当前读取的数据数量pos不等于声明的数据长度size,抛出异常,然后对堆栈进行pop操作,如果当前堆栈不为空,那么就在堆栈的栈顶的pos加上当前处理完毕的数据长度(用来处理这种情况-结构体的字段又是结构体,这种递归的结构)
// go-ethereum/rlp/decode.go
type listpos struct{ pos, size uint64 }
// pos字段记录了当前这个list已经读取了多少字节的数据, 所以刚开始的时候肯定是0。
// size字段记录了这个list对象一共需要读取多少字节数据。
// List starts decoding an RLP list. If the input does not contain a
// list, the returned error will be ErrExpectedList. When the lists
// end has been reached, any Stream operation will return EOL.
func (s *Stream) List() (size uint64, err error) {
// 获取类型kind和大小size
kind, size, err := s.Kind()
if err != nil {
return 0, err
}
if kind != List {
return 0, ErrExpectedList
}
// 类型匹配,所以把listpos压入栈,这个对象的pos字段记录了当前这个list已经读取了多少字节的数据
s.stack = append(s.stack, listpos{0, size})
s.kind = –1
s.size = 0
return size, nil
}
// ListEnd returns to the enclosing list.
// The input reader must be positioned at the end of a list.
func (s *Stream) ListEnd() error {
if len(s.stack) == 0 {
return errNotInList
}
// 取出listpos,如果当前读取的数据数量pos不等于声明的数据长度size,抛出异常
tos := s.stack[len(s.stack)–1]
if tos.pos != tos.size {
return errNotAtEOL
}
s.stack = s.stack[:len(s.stack)–1] // pop
if len(s.stack) > 0 {
s.stack[len(s.stack)–1].pos += tos.size
}
s.kind = –1
s.size = 0
return nil
}