首发于:公众号【3D视觉工坊】
欢迎加入国内最大的3D视觉交流社区,1700+的领域从业者正在共同进步~1、Nonlinear 3D Face Morphable Model(2018)
论文链接:https://arxiv.org/abs/1804.03786
项目链接:http://cvlab.cse.msu.edu/project-nonlinear-3dmm.html
主要思想:三维变形模型(3DMM)作为一种经典的三维人脸形状和纹理统计模型,在人脸分析、模型拟合、图像合成等领域有着广泛的应用。传统的3DMM是从一组控制良好的2D人脸图像中学习到的,并通过两组PCA基函数来表示。由于训练数据的类型和数量以及线性基的存在,使得3DMM的表示能力受到限制。针对这些问题,本文提出了一种新的框架,在不采集三维人脸扫描数据的情况下,从大量无约束的人脸图像中学习非线性3DMM模型,具体地说,在给定人脸图像作为输入的情况下,网络编码器估计投影、形状和纹理参数。两个解码器作为非线性3DMM分别从形状和纹理参数映射到三维形状和纹理。利用投影参数、三维形状和纹理,设计了一种新的解析可微绘制层来重建原始输入人脸。整个网络是端到端培训,只有薄弱的监督。我们证明了非线性3DMM比线性3DMM具有更好的表现力,以及它对人脸对齐和三维重建的贡献。
主要贡献:
1、 我们学习了一个非线性3DMM模型,它比传统的线性模型具有更大的表示能力。
2、 我们通过弱监控,利用大量没有三维扫描的二维图像,共同学习模型和模型拟合算法。新的渲染层实现了端到端的训练。
3、 新的3DMM进一步提高了相关任务的性能:人脸对齐和人脸重建
主要结构:
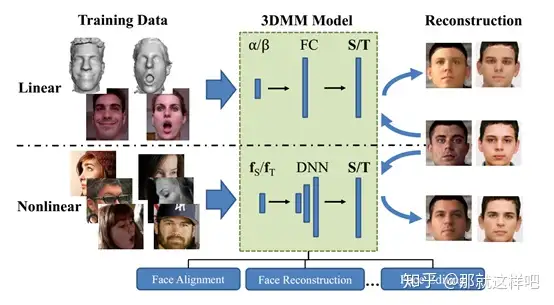
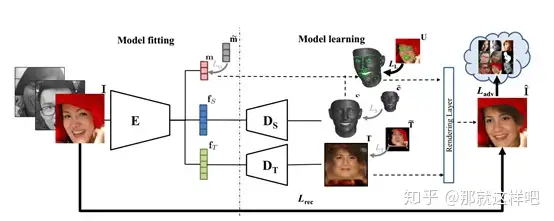
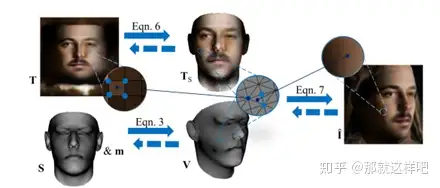
实验结果:





2、On Learning 3D Face Morphable Model from In-the-wild Images(2019)
论文链接:https://arxiv.org/abs/1808.09560
项目链接:http://cvlab.cse.msu.edu/project-nonlinear-3dmm.html
本篇和Nonlinear 3D Face Morphable Model是同一作者,在原有文章的基础做了相关提升和改进~
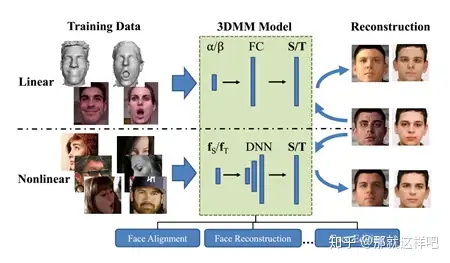
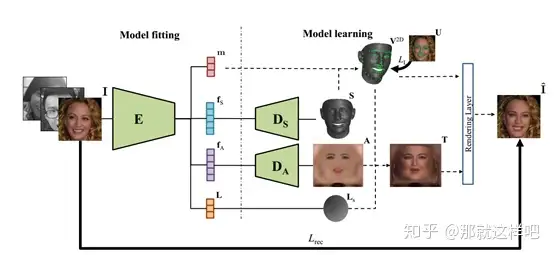
主要思想:三维变形模型(3DMM)作为一种经典的三维人脸形状和反照率的统计模型,在人脸分析、模型拟合、图像合成等方面有着广泛的应用。传统的3DMM是从一组具有良好控制的二维人脸图像的三维人脸扫描中学习而来,并由两组PCA基函数表示。由于训练数据的类型和数量以及线性基的存在,使得3DMM的表示能力受到限制。为了解决这些问题,本文提出了一个新的框架,在不采集三维人脸扫描的情况下,从大量的新的原始人脸图像中学习非线性3DMM模型。具体地说,给定一个人脸图像作为输入,网络编码器估计投影、光照、形状和反照率参数。两个解码器作为非线性3DMM分别从形状和反照率参数映射到三维形状和反照率。利用投影参数、光照、三维形状和反照率,设计了一种新的解析可微渲染层来重建原始输入人脸。整个网络是端到端培训,只有薄弱的监督。展示了非线性3DMM相对于线性3DMM的优越表现力,以及它对人脸对齐、三维重建和人脸编辑的贡献。
主要创新:
1、 我们学习了一个非线性的3DMM模型,它完全模拟了形状、反照率和光照,比传统的线性模型具有更大的表示能力。
2、 形状和反照率都表示为二维图像,这有助于保持空间关系,并在图像合成中利用CNN的优势。
3、 我们通过弱监督联合学习模型和模型拟合算法,利用大量未经三维扫描的二维图像,并且新的渲染层实现了端到端的训练。
4、 新的3DMM进一步提高了人脸对齐、人脸重建和人脸编辑相关任务的性能。
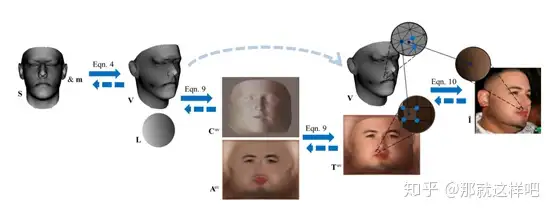
主要结构:
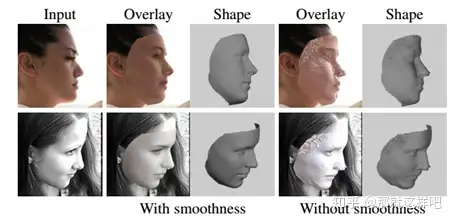
实验结果:


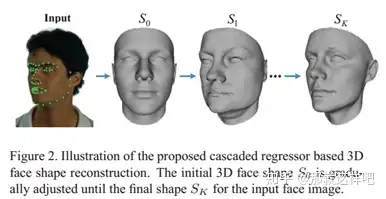
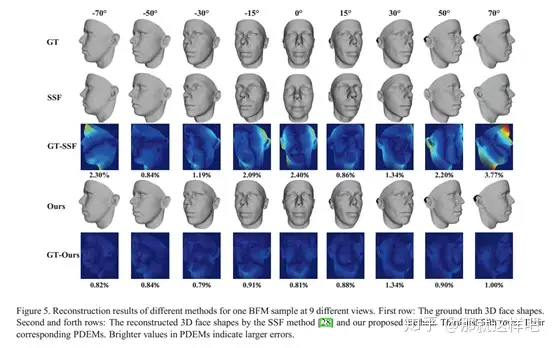
3、Cascaded Regressor based 3D Face Reconstruction from a Single Arbitrary View Image(2015)
论文链接:https://arxiv.org/abs/1509.06161v1
主要思想:最新的方法是通过将三维人脸模型拟合到输入图像或直接学习二维图像和三维人脸之间的映射函数,从单个图像重建三维人脸形状。然而,由于昂贵的在线优化或正面人脸图像的要求,它们通常很难在实际应用中使用。本文将三维人脸重建问题归结为回归问题,而不是模型拟合问题。给定一个输入的人脸图像及其上的一些预定义的人脸标志,根据输入的标志与从重建的三维人脸上获得的标志之间的偏差,通过级联回归器计算初始三维人脸形状的一系列形状调整。级联回归器离线学习从一组三维面及其在不同视图中对应的二维面图像。该方法将大视角下不可见的标志点视为缺失数据,用相同的回归函数统一处理任意视角下的人脸图像。在BFM和BPASRORUS数据库上的实验表明,该方法能够比现有方法更有效、更准确地重建任意视角图像的三维人脸。
主要创新点:本文旨在开发一种能处理任意视角人脸图像的实时三维人脸重建算法。为此,我们从一个初始的3D人脸形状开始,根据输入的2D人脸图像中的一些带注释的标志点和离线学习的一系列回归函数逐步调整它。使用的landmarks集合对于所有不同的视图都是一致的,并且当landmarks由于大视角而不可见时,它将被标记为缺少数据。该方法避免了复杂的在线优化问题,能有效地统一处理任意视角的人脸图像。在回归器离线训练过程中,优化目标是使估计的三维人脸形状与真实的三维人脸形状之间的总误差最小,这保证了重建精度高于基于3DMM的方法,该方法只考虑了标志点的适应度,而不考虑整个三维人脸。
实验结果:
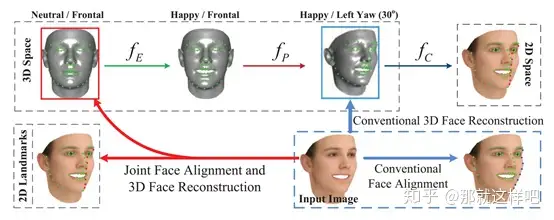
4、JointFace Alignment and 3D Face Reconstruction(ECCV2016)
论文链接:
主要思想:提出了一种从任意姿态和表情的二维人脸图像中同时解决人脸对齐和三维重建两个问题的方法。该方法采用两组级联回归器,一组用于更新2D landmarks,另一组用于更新重建的pose-expression标准化(PEN)三维人脸形状。通过3D-to-2D映射矩阵将三维人脸形状和标志点关联起来。在每次迭代中,首先通过一个地标回归器估计对地标的平差,然后利用该地标平差通过一个形状回归器估计三维人脸形状平差。根据调整后的三维人脸形状和2D landmarks计算三维到二维的映射,进一步细化2D landmarks。基于带注释的三维人脸形状与二维人脸图像的配对训练数据集,设计了一种有效的回归学习算法。与现有的方法相比,所提出的方法能够从单个2D人脸图像中实时自动地生成笔3D人脸形状,并定位可见和不可见的2D landmarks。大量的实验表明,该方法在人脸对齐和三维重建方面都能达到最新的精度。
主要贡献:本文提出在一个统一的框架内同时解决人脸对齐和三维人脸形状重建两个问题。为此,从一组带注释的二维人脸图像和三维人脸形状的配对训练集中联合学习两组回归器。这两组回归函数交替应用于输入二维图像上的标志点定位,同时重建其姿态表达式规范化(PEN)三维人脸形状。
主要结构:
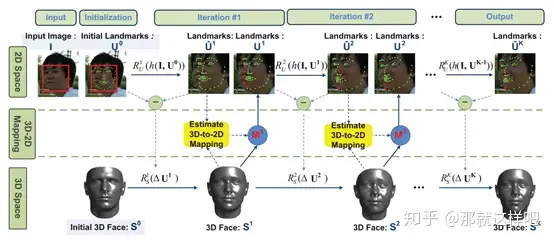
实验结果:

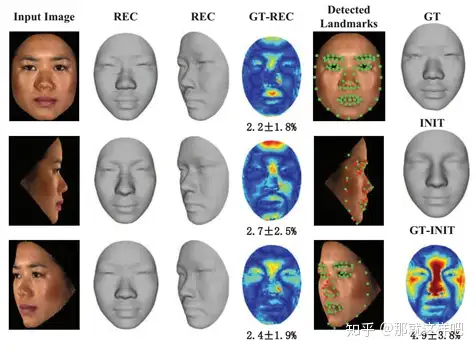
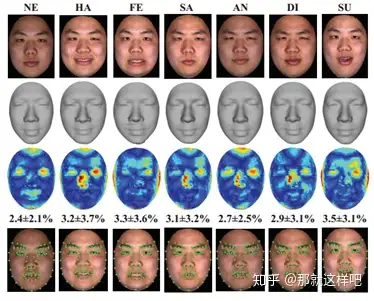
5、Photo-Realistic Facial Details Synthesis From Single Image(ICCV2019 oral)
论文链接:https://arxiv.org/pdf/1903.10873.pdf
代码链接:https://github.com/apchenstu/Facial_Details_Synthesis
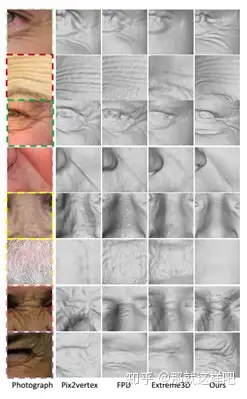
主要思想:我们提出了一种单图像三维人脸合成技术,它可以处理具有挑战性的面部表情,同时恢复精细的几何细节。该方法利用表情分析生成代理人脸几何,并结合有监督和无监督学习进行人脸细节合成。在代理生成方面,我们进行情感预测,以确定一个新的表达信息代理。在细节合成方面,我们提出了一种基于条件生成对抗网(CGAN)的深度人脸细节网(DFDN),它同时使用了几何和外观损失函数。对于几何学,我们从122个不同的受试者的3个面部表情下采集了366个高质量的三维扫描。对于外观,我们使用额外的163K在野生脸图像和应用基于图像的渲染,以适应光线的变化。综合实验表明,该框架能够在具有挑战性的面部表情下,生成具有真实细节的高质量三维人脸。
主要结构:
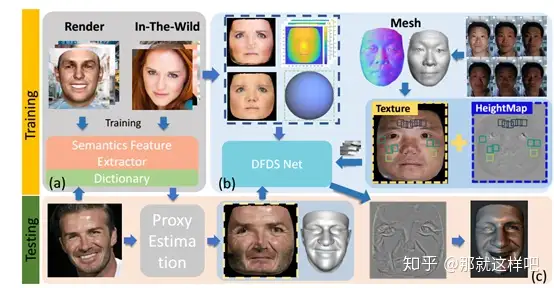
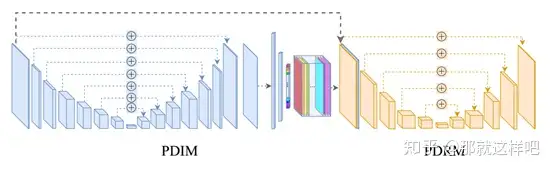

实验结果:


6、FML: Face Model Learning from Videos,CVPR 2019 (Oral)
论文链接:https://arxiv.org/pdf/1812.07603.pdf
主要思想:基于单目图像的人脸三维重建是计算机视觉中一个长期存在的问题。由于图像数据是三维人脸的二维投影,因此产生的深度模糊使问题不适定。
大多数现有的方法依赖于从有限的3D人脸扫描构建的数据驱动先验。相比之下,本文提出了基于多帧视频的深度网络自监督训练,即(i)在形状和外观上学习人脸识别模型,同时(ii)联合学习重建三维人脸。本文中的脸部模型只使用从网上收集的视频片段的语料库来学习。这种几乎无休止的训练数据源使学习高度通用的三维人脸模型成为可能。为了实现这一点,提出了一种新的多帧一致性损失方法,该方法可以保证被摄体面部多帧图像的形状和外观一致,从而最小化深度模糊度。在测试时,可以使用任意数量的帧,这样既可以进行单目重建,也可以进行多帧重建。
主要贡献:
1、 一种深度神经网络,它从包含每个对象的多个图像(如多视图序列,甚至单目视频)的无约束图像的大数据集中学习面部形状和外观空间。
2、 通过投影到blendshape下的nullspace上来实现多帧一致性丢失的显式blendshape和标识分离。
3、 一种新的基于连体网络的多帧身份一致性丢失算法。
网络结构:


实验结果:




7、Large Pose 3D Face Reconstruction from a Single Image via Direct Volumetric(2017)
论文链接:https://arxiv.org/abs/1703.07834
主要思想:三维人脸重建是计算机视觉中一个非常困难的基本问题。当前的系统通常假设多个面部图像(有时来自同一个主题)作为输入,并且必须解决一些方法上的挑战,例如在大型面部姿势、表情和非均匀照明之间建立密集的对应关系。一般来说,这些方法需要复杂而低效的pipelines来建模和拟合。在这项工作中,本文建议通过在由二维图像和三维面部模型或扫描组成的适当数据集上训练卷积神经网络(CNN)来解决许多这些限制。论文的CNN只处理一个二维的面部图像,不需要精确的对齐,也不需要在图像之间建立紧密的对应关系,适用于任意的面部姿势和表情,并可用于重建整个三维面部几何结构(包括面部的不可见部分),绕过三维可变形模型的构建(在训练期间)和拟合(在测试期间)。本文通过一个简单的CNN架构来实现这一点,该架构从单个2D图像执行3D面部几何体的体积表示的直接回归。论文还演示了如何将面部标志点定位的相关任务融入到所提出的框架中,并帮助提高重建质量,特别是在大姿态和面部表情的情况下。
主要贡献:
1、 在给定由二维图像和三维面部扫描组成的数据集的情况下,本文研究CNN是否能够以端到端的方式直接学习从图像像素到完整的三维面部结构几何(包括不可见的面部部分)。事实上,论文表明这个问题的答案是肯定的。
2、 本文的CNN只处理单一的二维面部图像,不需要精确对齐,也不需要在图像之间建立紧密的对应关系,适用于任意的面部姿势和表情,并且可以用于重建整个三维面部几何体,而不必经过以下步骤的构造(训练期间)和拟合(测试期间)3毫米。
3、 通过一个简单的CNN架构实现这一点,该架构从单个2D图像直接回归3D面部几何图形的体积表示。
4、 展示了如何将三维面部地标定位的相关任务纳入到所提出的框架中,并帮助提高重建质量,特别是在大姿态和面部表情的情况下。
5、 论文的方法在单图像三维人脸重建方面的性能大大优于以前的工作。
主要结构:

实验结果:


8、Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network(PRNet,ECCV2018)
论文链接:https://arxiv.org/pdf/1803.07835.pdf
代码链接:https://github.com/YadiraF/PRNet
主要思想:提出了一个简单的方法,同时重建三维面部结构,并提供密集的对齐。为了实现这一目标,设计了一种称为UV位置图的二维表示方法,该方法在UV空间中记录完整人脸的3D形状,然后训练一个简单的卷积神经网络将其从单个2D图像中回归。在训练过程中,还将一个权重掩码集成到损失函数中,以提高网络的性能。本文的方法不依赖于任何先验人脸模型,可以在语义的同时重建完整的人脸几何。同时,网络本身很轻,处理图像的时间只有9.8毫秒,这比以前的作品要快得多。在多个具有挑战性的数据集上的实验表明,论文提出的方法在重建和对齐任务上都大大超过了其它最先进的方法。
主要贡献:
1、 第一次以端到端的方式解决了人脸对齐和三维人脸的问题,使其一起完成,而且不受低维解空间的限制。
2、 为了直接回归三维面部结构和密集排列,开发了一种新的表示方法,称为UV位置图,它记录了三维人脸的位置信息,并与UV空间上每个点的语义紧密对应。
3、 为了训练,提出了一个权重掩码,它将不同的权重分配给位置图上的每个点并计算加权损失。论文展示这个设计有助于提高网络的性能。
4、 最终提供了一个运行速度超过100FPS的轻量级框架直接从单个二维图像中获得三维人脸重建和对齐结果面部图像。
主要结构:


实验结果:


9、Joint 3D Face Reconstruction and Dense Face Alignment from A Single Image with 2D-Assisted Self-Supervised Learning(2019,2DASL)
论文链接:https://arxiv.org/abs/1903.09359
主要思想:从单个二维图像重建三维人脸是一个具有广泛应用前景的挑战性问题。
最新的方法通常旨在学习基于CNN的3D人脸模型,该模型从2D图像中回归3D可变形模型(3DMM)的系数,以呈现3D人脸重建或稠密的人脸对齐。然而,由于三维标注训练数据的不足,极大地限制了这些方法的性能。为了解决这一问题,本文提出了一种新的二维辅助自监督学习(2DASL)方法,该方法可以有效地利用具有噪声路标信息的二维人脸图像,从而大大提高三维人脸模型的学习效率。具体来说,2DSAL以稀疏的二维人脸标志为补充信息,提出了四种新的自监督方案,将二维标志和三维标志的预测看作是一个自映射过程,包括二维和三维标志的自预测一致性、二维标志预测的周期一致性和二维标志预测的自评性基于地标预测的3DMM系数预测。使用这四种自监督方案,2DASL方法显著地减轻了对传统的成对2D-to-3D注释的要求,并且在不需要任何额外3D注释的情况下,给出了更高质量的3D人脸模型。多个具有挑战性的数据集上的实验表明,本文的方法在三维人脸重建和密集人脸对齐方面都有很大的优势。
主要贡献:
1、 本文提出了一种新的方案,旨在充分利用丰富的二维人脸图像来辅助三维人脸模型学习。这是一种新的方法,不同于大多数常用的通过收集更多带有3D注释的数据进行模型训练来改进3D人脸模型的方法。
2、 我们介绍了一种新的方法,该方法能够通过自监督学习训练具有二维人脸图像的三维人脸模型。设计的多种形式的自我监督是有效的和数据有效的。
3、 开发了一种新的基于自评学习的方法,该方法可以有效地改进三维人脸模型的学习过程,并给出一个更好的模型,即使二维地标标注是噪声的。
4、 在AFLW2000-3D和AFLW-LFPA数据集的比较表明,本文的方法在三维人脸重建和密集人脸对齐两方面都取得了优异的性能。
模型结构:


实验结果:



10、Face Alignment Across Large Poses: A 3D Solution(3DDFA)
论文链接:https://arxiv.org/pdf/1511.07212.pdf
代码链接:http://www.cbsr.ia.ac.cn/users/xiangyuzhu/
主要思想:人脸对齐是CV领域的一个重要研究课题,它将人脸模型与图像进行匹配,提取人脸像素的语义信息。然而,大多数算法都是为中小型(45°以下)的人脸设计的,缺乏在大型姿态下对齐人脸的能力高达90度。挑战有三个方面:首先,常用的基于地标的人脸模型假设所有的landmark都是可见的,因此不适合于剖面视图。其次,在大姿态下,从正面到侧面,脸部的外观变化更大。第三,在大姿态下标记landmark是非常具有挑战性的,因为不可见的landmark必须被猜测。本文提出了一种新的三维稠密人脸对齐框架(3DDFA)来解决这三个问题,该框架通过卷积神经网络(CNN)将稠密的三维人脸模型拟合到图像上。除此之外,还提出了一种在剖面视图中合成大规模训练样本的方法,以解决第三个数据标记问题。在具有挑战性的AFLW数据库上的实验表明,我们的方法比最新的方法有了显著的改进。
主要贡献:
1、 为了解决大姿态下不可见标志的问题,提出了一种基于三维稠密人脸模型而非稀疏标志形状模型的图像匹配方法。通过合并三维信息,可以内在地解决由三维变换引起的外观变化和自遮挡问题。我们称之为三维密集面对齐(3DDFA)。
2、为了解决3DDFA中的拟合问题,提出了一种基于级联卷积神经网络(CNN)的回归方法。在这项工作中,采用CNN来拟合具有特定设计特征的三维人脸模型,即投影标准化坐标代码(PNCC)。此外,提出了加权参数距离损失(WPDC)作为损失函数,这是第一次尝试用CNN解决三维人脸对齐问题。
3、 为了实现三维人脸分析的训练,构造了一个包含两对二维人脸图像和三维人脸模型的人脸数据库。进一步提出了一种人脸轮廓算法来合成60k+的大姿态训练样本。合成的样本能够很好地模拟人脸在大姿态下的外观,提高了先前提出的人脸对齐算法的性能。
模型结构:



实验结果:


往期干货资源:
汇总 | 国内最全的3D视觉学习资源,涉及计算机视觉、SLAM、三维重建、点云处理、姿态估计、深度估计、3D检测、自动驾驶、深度学习(3D+2D)、图像处理、立体视觉、结构光等方向!
汇总 | 三维重建算法实战(单目重建、立体视觉、多视图几何)