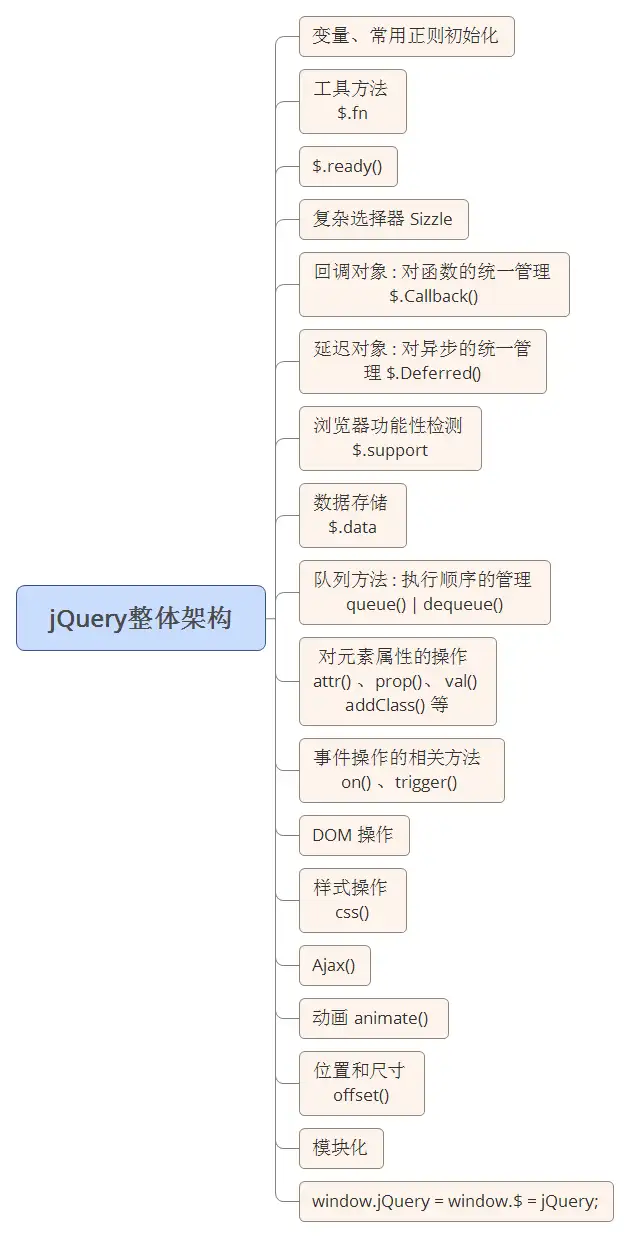
先看jQuery的整体框架(v2.0.3)
(function(){
})();
可以看到,jQuery源码结构非常清晰,接下来我们逐一分析源码中主要部分及其精髓实现原理,我会在接下来几篇文章来对jQuery源码进行解析。
一、jQuery 闭包结构
几乎稍微有点经验前端人员都这么做,为了避免声明了一些全局变量而污染,把代码放在一个“沙箱执行”,然后在暴露出命名空间(可以为API,函数,对象):
有人会疑问,为什么要第二个参数undefined 。在这里,jquery中有一个针对压缩的小小策略。
先看以下代码:
经过压缩后,可以变成:
因为这个外层函数只传了一个参数,因此沙箱执行时,u自然会undefined,把9个字母缩成1个字母,可以看出压缩后的代码减少一些字节数。
沙箱中第一句”use strict”;是表示使用javascript的严格模式,对于低级的浏览器,这里相当一字符串,所以兼容性是没问题的,详细的话,在阮一峰的文章Javascript 严格模式详解有介绍。
二、jQuery 无 new 构造
嘿,回想一下使用 jQuery 的时候,实例化一个 jQuery 对象的方法:
大部分人使用 jQuery 的时候都是使用第一种无 new 的构造方式,直接 $() 进行构造,这也是 jQuery 十分便捷的一个地方。当我们使用第一种无 new 构造方式的时候,其本质就是相当于 new jQuery(),那么在 jQuery 内部是如何实现的呢?看看:
大部分人初看 jQuery.fn.init.prototype = jQuery.fn 这一句都会被卡主,很是不解。但是这句真的算是 jQuery 的绝妙之处。理解这几句很重要,分点解析一下:
1)首先要明确,使用 $(xxx) 这种实例化方式,其内部调用的是 return new jQuery.fn.init(selector, context, rootjQuery) 这一句话,也就是构造实例是交给了 jQuery.fn.init() 方法去完成。
2)将 jQuery.fn.init 的 prototype 属性设置为 jQuery.fn,那么使用 new jQuery.fn.init() 生成的对象的原型对象就是 jQuery.fn ,所以挂载到 jQuery.fn 上面的函数就相当于挂载到 jQuery.fn.init() 生成的 jQuery 对象上,所有使用 new jQuery.fn.init() 生成的对象也能够访问到 jQuery.fn 上的所有原型方法。
3)也就是实例化方法存在这么一个关系链
jQuery.fn.init.prototype = jQuery.fn = jQuery.prototype ;new jQuery.fn.init() 相当于 new jQuery() ;jQuery() 返回的是 new jQuery.fn.init(),而 var obj = new jQuery(),所以这 2 者是相当的,所以我们可以无 new 实例化 jQuery 对象。三、jQuery 方法的重载
jQuery 源码晦涩难读的另一个原因是,使用了大量的方法重载,但是用起来却很方便:
方法的重载即是一个方法实现多种功能,经常又是 get 又是 set,虽然阅读起来十分不易,但是从实用性的角度考虑,这也是为什么 jQuery 如此受欢迎的原因,大多数人使用 jQuery() 构造方法使用的最多的就是直接实例化一个 jQuery 对象,但其实在它的内部实现中,有着 9 种不同的方法重载场景:
所以读源码的时候,很重要的一点是结合 jQuery API 进行阅读,去了解方法重载了多少种功能,同时我想说的是,jQuery 源码有些方法的实现特别长且繁琐,因为 jQuery 本身作为一个通用性特别强的框架,一个方法兼容了许多情况,也允许用户传入各种不同的参数,导致内部处理的逻辑十分复杂,所以当解读一个方法的时候感觉到了明显的困难,尝试着跳出卡壳的那段代码本身,站在更高的维度去思考这些复杂的逻辑是为了处理或兼容什么,是否是重载,为什么要这样写,一定会有不一样的收获。其次,也是因为这个原因,jQuery 源码存在许多兼容低版本的 HACK 或者逻辑十分晦涩繁琐的代码片段,浏览器兼容这样的大坑极其容易让一个前端工程师不能学到编程的精髓,所以不要太执着于一些边角料,即使兼容性很重要,也应该适度学习理解,适可而止。
四、$.ready的实现原理
只要使用过jQuery的,想必对ready都不陌生,$(function(){})和$(document).ready(function(){})的使用更是习以为常。
要说到window.onload与document.ready的区别也能谈出个一二,最重要的区别就是:
window.onload是在dom文档树以及所有文件都加载完成后,才执行;
而document.ready是,只要dom文档树加载完,就执行,且当dom文档树加载完就执行的好处就是,当页面中的图片等外部资源过多时,window.onload迟迟不能触发,这时若还没有绑定事件,用户点击按钮时没有反应,这不影响用户体验么。
咦,Jquery的ready这么牛逼,那Jquery是怎么实现ready这个函数的呢?我们不妨一起来探究探究。
以下Jquery.ready的源码,截自于jQuery 1.12.0。
从上面的源码中,可以看出,jQuery.ready主要通过以下几个东东来判断dom文档树是否加载完成:
(1) document.readyState
(2) DOMContentLoaded
(3) onreadystatechange
(4) doScroll
下面,我们就一步一步来解析
1、 document.readyState
readyState是个什么东东呢?它是document的一个属性值,返回当前文档的状态,该属性会根据文档加载情况,返回如下几个属性值:
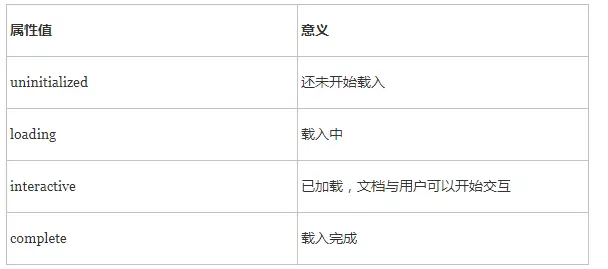
从属性值,可得知,倘若当我们判断document.readyState为complete,那么DOM文档树就是加载完毕。但,从上面源码注释(6–11行)中可以得知ChrisS发现了一个很特别的问题,所以我们在判断document.readyState === ‘complete’后,执行jQuery.ready,需要延迟一下。但上面的代码中,怎么没有延迟时间呢?
那是因为倘若我们没有设置延迟时间,setTimeout就会根据当前浏览器及操作系统,自动给它设定一个最小延迟时间。在《JavaScript忍者的秘密》中曾提到:

2、 DOMContentLoaded事件
从上面的源代码注释中,可以看出DOMContentLoaded是基于标准的浏览器的。
那么它的作用是什么呢?
当DOM文档树加载完成后,即触发。
所以可以在标准的浏览器中判断DOMContentLoaded,来判断DOM树,是否加载完成。
3、 onreadystatechange事件
上面的DOMContentLoaded事件是基于标准的浏览器的,那倘若不标准的呢,如IE,则使用onreadystatechange事件。
咦,怎么感觉如此熟悉。
XMLHttpRequest—>Ajax。想起来了么。在IE中onreadystatechange是私有化的,即所有元素都存在onreadystatechange事件,而W3C标准中,仅XMLHttpRequest对象中存在onreadystatechange事件。所以当事件触发时,倘若onreadystatechange === complete,则可视为DOM树加载完成。
4、 doScroll
从上面的源码中的注释(49–50行),可得,Diego Perini报告一种检测IE下DOM文档是否加载完成的方法,即,使用doScroll。
咦,上面onreadystatechange事件,不是能处理了吗?!!
是的,但是它有个弊端,就是当页面中存在图片时,可能反而会晚于onload事件后,触发。
为什么呢?
因为我们是依据onreadystatechange === complete来判断的嘛,如果图片没加载或者正在加载中,那么onreadystatechange就不等于complete了哦。
所以为了保险起见,再用doScroll来检测。
doScroll的原理就是,当页面DOM未加载完成时,调用doScroll方法,会产生异常。所以利用try-catch来对doScroll捕获异常就可以判断DOM文档是否加载完咯。
未完待续……