leveldb总体架构sstable文件的生成过程sstable中的blockfitler_block写入流程读取流程sstable文件的生成与合并版本管理与版本恢复LruCache机制参考链接
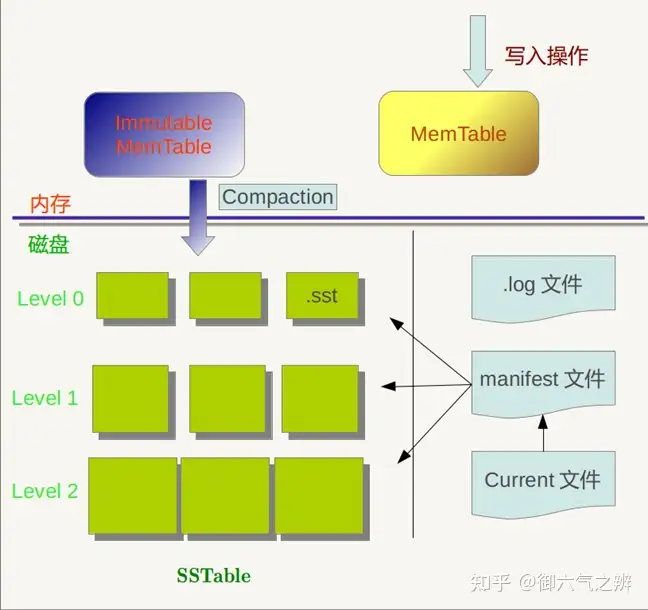
leveldb总体架构
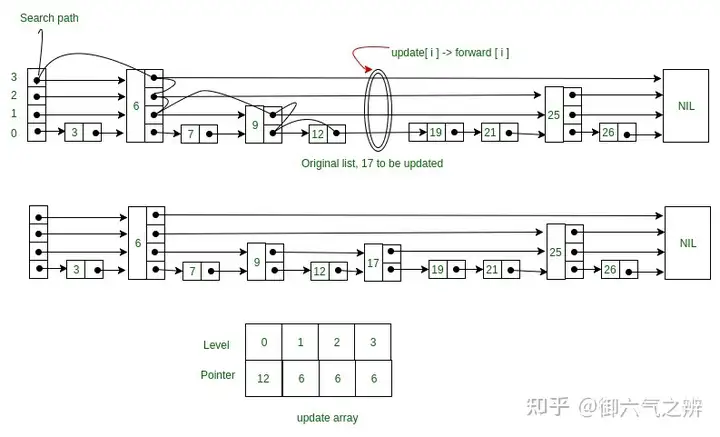
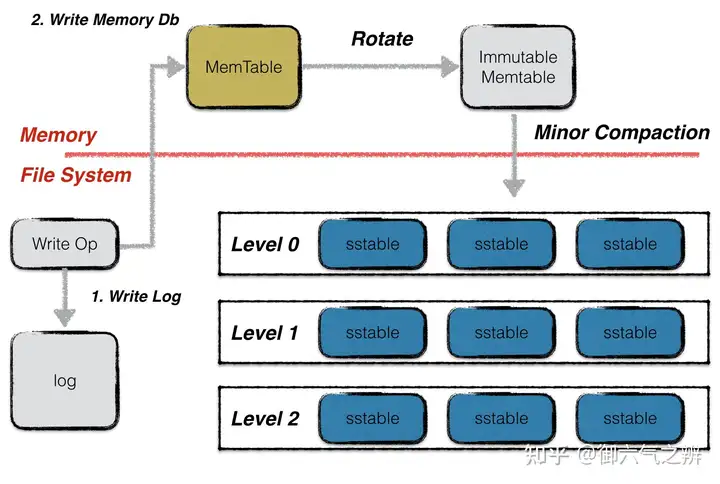
leveldb总体架构memtable:内存中的数据结构,写入操作会将数据写入其中,采用skiplist实现。skiplist由多层级单向有序链表组成,相对于平衡树,其代码简单,搜索、插入和删除的平均复杂度是O(logn),开源的NO SQL数据库redis内部实现同样采用了skiplist。
skiplist结构 Immutable Memtable: 写入数据的时候,会先去检查Memtable的当前大小。当到达指定阈值的时候,会把Memtable置为Immutable Memtable。 Immutable Memtable不会允许数据写入。这时候会主动触发一次compaction,将Immutable Memtable转成sstable,并放置于一个合适的level层中。
log文件:写操作的时候会通过顺序写的方式优先写到这个文件,然后再写入上面的memtable。避免机器宕机的时候,内存数据丢失。所以写操作,实际上是一次顺序写磁盘操作+一次内存操作。
sstable: 磁盘的存储文件。文件分level存放。每个文件内的数据按key有序存储。sstable文件是由内存中的Immutable Memtable落地到磁盘中生成或者由本层的文件和上一层的文件做归并排序合并生成。除了level0,其他层level内不同文件之间key的范围不会存在重叠。manifest文件:磁盘上的文件。用来描述sstable在各个level的分布,以及每个sstable最小key、最大key和文件size,记录着leveldb的初始版本信息以及每一次版本变更的增量数据。current文件:磁盘上的文件。存储着当前的manifest文件名。
sstable文件的生成过程
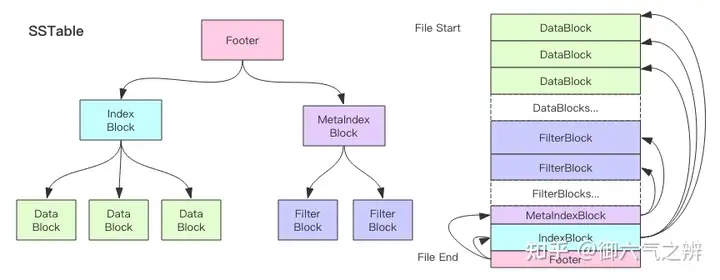
sstable文件结构
遍历immutable memtable的key-value,将其写入data_block,每当data_block大小达到指定值时,构造另外一个key-value写入index_block,其中key为data_block的最大key,value为data_block在sstable中的偏移和大小。同时,在生成data_block的过程中,会构造一个filter_block,默认使用bloom filter的策略生成,用来判断一个查找key是否在data_block中,提高leveldb的读取性能。immutable memtable的所有key-value写入之后,会生成一个meta_index_block来存储所有filter_block在sstable文件中的偏移和大小(这种策略可以使得将来可以支持生成多个filter_block,进一步提升读取性能)。meta_index_block和index_block的偏移和大小则保存在sstable的脚注footer中。
sstable中的block
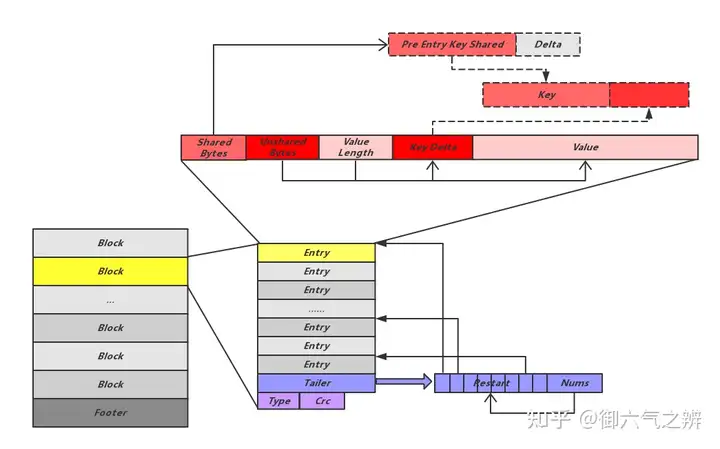
block的存储布局
一个简单block的实例
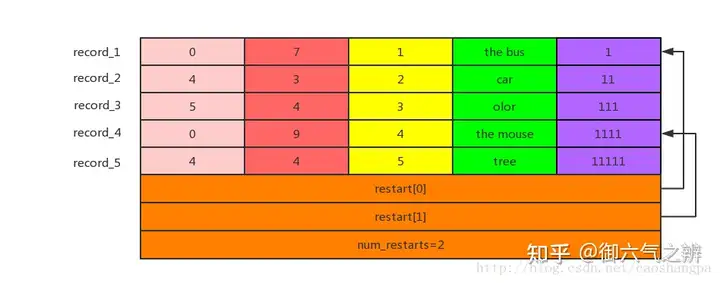
data_block、index_block和meta_index_block的结构都是如此。 由于leveldb中的数据是按照key的字典顺序存储的,为了提高空间存储效率,对key采用前缀压缩的方法。但如此一来查找某一key都必须从第一个key开始遍历才能恢复,因此每间隔block_restart_interval个key-value,就全量存储一个key,并设置一个restart point。leveldb将每个block分成多个相邻的key-value组成的集合,以这些集合为单位进行前缀压缩,并将每个集合的起始key-value在block中的的偏移位置放在数据区的后面,因此通过这个找到起始位置就可以找到压缩集合,找到压缩集合就可以将集合中的每个key进行解码恢复。其中每一个restart都指向一个前缀压缩集合的起始点的偏移位置。最后一个32bit存储的是restart数组的大小,也就是该block一共有多少个前缀压缩集合。The tail end of the block stores the offsets of all of the restart points, and can be used to do a binary search when looking for a particular key。
fitler_block
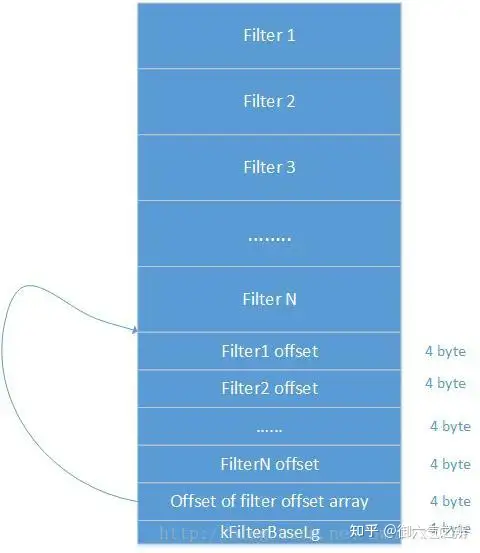
filter_block内部结构
在将每一对key-value写入data_blcok的同时,FilterBlockBuilder也存储了一个key集合,当一个新data_block写入完成后,FilterBlockBuilder会根据data_block的偏移来决定是否对之前积累的key集合生成一份bit位图存入filter_block,生成bit位图后清空key集合,重新开始存储下一份key集合。
void FilterBlockBuilder::StartBlock(uint64_t block_offset) {
uint64_t filter_index = (block_offset / kFilterBase);
assert(filter_index >= filter_offsets_.size());
while (filter_index > filter_offsets_.size()) {
GenerateFilter();
}
}
void FilterBlockBuilder::GenerateFilter() {
const size_t num_keys = start_.size();
if (num_keys == 0) {
// Fast path if there are no keys for this filter
filter_offsets_.push_back(result_.size());
return;
}
// Make list of keys from flattened key structure
start_.push_back(keys_.size()); // Simplify length computation
tmp_keys_.resize(num_keys);
for (size_t i = 0; i < num_keys; i++) {
const char* base = keys_.data() + start_[i];
size_t length = start_[i + 1] – start_[i];
tmp_keys_[i] = Slice(base, length);
}
// Generate filter for current set of keys and append to result_.
filter_offsets_.push_back(result_.size());
policy_->CreateFilter(&tmp_keys_[0], static_cast<int>(num_keys), &result_);
tmp_keys_.clear();
keys_.clear();
start_.clear();
}
写入流程
leveldb写入流程首先在写入前会先确保当前的存储状态符合条件。 1.当level 0层的文件数达到config::kL0_SlowdownWritesTrigger时则会延迟写。 2.当此时的memtable还有内存空间则允许写入。 3.当immutable table正在落地成sstable时则会停止写入直到其落地结束。 4.当level 0层的文件数达到config::kL0_StopWritesTrigger时则会停止写入直到sstable compaction使得level 0层的文件数达到写入要求。 5.其它情况,则将旧的memtable置为immutable,并新建一个memtable用于写入,然后将immutable memtable落地生成sstable放于合适的level层中。
Status DBImpl::MakeRoomForWrite(bool force) {
mutex_.AssertHeld();
assert(!writers_.empty());
bool allow_delay = !force;
Status s;
while (true) {
if (!bg_error_.ok()) {
// Yield previous error
s = bg_error_;
break;
} else if (allow_delay && versions_->NumLevelFiles(0) >=
config::kL0_SlowdownWritesTrigger) {
mutex_.Unlock();
env_->SleepForMicroseconds(1000);
allow_delay = false; // Do not delay a single write more than once
mutex_.Lock();
} else if (!force &&
(mem_->ApproximateMemoryUsage() <= options_.write_buffer_size)) {
// There is room in current memtable
break;
} else if (imm_ != nullptr) {
// We have filled up the current memtable, but the previous
// one is still being compacted, so we wait.
Log(options_.info_log, “Current memtable full; waiting…\n“);
background_work_finished_signal_.Wait();
} else if (versions_->NumLevelFiles(0) >= config::kL0_StopWritesTrigger) {
// There are too many level-0 files.
Log(options_.info_log, “Too many L0 files; waiting…\n“);
background_work_finished_signal_.Wait();
} else {
// Attempt to switch to a new memtable and trigger compaction of old
assert(versions_->PrevLogNumber() == 0);
uint64_t new_log_number = versions_->NewFileNumber();
WritableFile* lfile = nullptr;
s = env_->NewWritableFile(LogFileName(dbname_, new_log_number), &lfile);
if (!s.ok()) {
// Avoid chewing through file number space in a tight loop.
versions_->ReuseFileNumber(new_log_number);
break;
}
delete log_;
delete logfile_;
logfile_ = lfile;
logfile_number_ = new_log_number;
log_ = new log::Writer(lfile);
imm_ = mem_;
has_imm_.store(true, std::memory_order_release);
mem_ = new MemTable(internal_comparator_);
mem_->Ref();
force = false; // Do not force another compaction if have room
MaybeScheduleCompaction();
}
}
return s;
}
将写操作写入日志
写入的日志内容
1条日志记录的内容包括当前db的sequence number、 本次日志记录中所包含的put/del操作的个数、本次操作的所有key-value键值对。WriteBatch的batch_data包含一个或者多个key-value键值对,从写入流程看到leveldb存在延迟写和停止写的情况,所以写队列的writebatch可能会存在堆积,为了优化写入性能,leveldb写入时会尽可能地合并多个WriteBatch的batch_data。日志文件不会记录所有的key-value,只会存储写入当前memtable中的key-value,因为leveldb每申请一个新memtable时也会新生成一个日志文件。
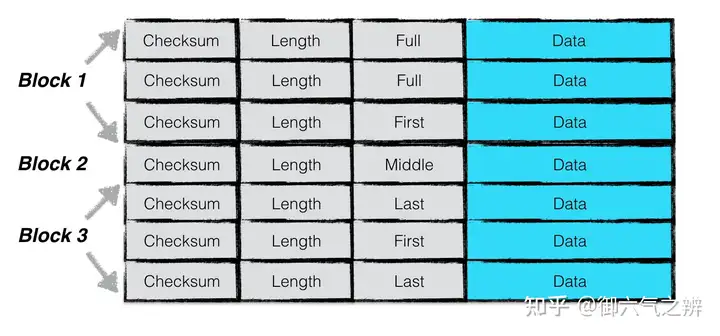
日志文件的结构
leveldb在写日志时,对日志文件进行了划分为多个32K的文件块,每次读写日志时都以这样的每个32K为单位。每次写入的日志记录块可能占用1个或者1个以上的文件块,因此日志记录块可以分为Full、First、Middle、Last4种类型,后面3种类型在读取的时候需要进行拼接。 – 依次将key-value写入到memtable内存中。
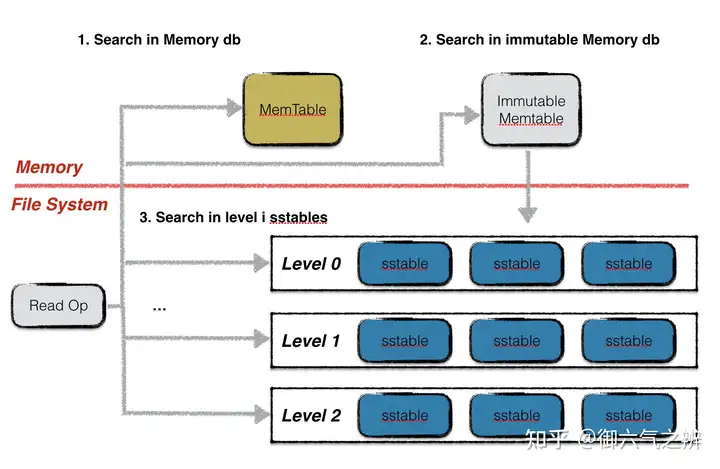
读取流程
读取流程在memtable中查找指定的key,若搜索到符合条件的数据项,结束查找。在immutable memtable中中查找指定的key,若搜索到符合条件的数据项,结束查找。按低层至高层的顺序在level i层的sstable文件中查找指定的key,若搜索到符合条件的数据项,结束查找,否则继续查询下一层level的sstable文件。
struct FileMetaData {
FileMetaData() : refs(0), allowed_seeks(1 << 30), file_size(0) {}
int refs;
int allowed_seeks; // Seeks allowed until compaction
uint64_t number;
uint64_t file_size; // File size in bytes
InternalKey smallest; // Smallest internal key served by table
InternalKey largest; // Largest internal key served by table
};
注意leveldb在每一层sstable中查找数据时,都是按序依次查找sstable的。 0层的文件比较特殊。由于0层的文件中可能存在key重合的情况,因此在0层中,需要遍历与查找key有重叠的所有文件。注意文件编号大的sstable优先查找,理由是文件编号较大的sstable中存储的总是最新的数据。 非0层文件,一层中所有文件之间的key不重合,因此leveldb可以借助版本信息中sstable的元数据(一个文件中最小与最大的key值)进行2分搜索快速定位,每一层只需要查找一个sstable文件的内容。
具体在某一sstable文件查找key的流程从LruCache中读取table信息,如果cache中没有,则打开sstable文件读取index_block、meta_index_block和filter_block信息,然后insert到LruCache中,LruCache的key为sstable的文件编号。通过index_block信息定位到key所在的data_block,由data_block的偏移可以拿到filter过滤器的bit位图进而可以迅速判断出该data_block中是否存在该key,如果存在则继续读取data_block内容查找(bloom filter存在一定的误判率)。从LruCache中读取data_block,如果cache中没有,则从sstable文件读取data_block数据,然后insert到LruCache中,LruCache的key为table的cache_id+data_block的文件偏移。可以通过data_block的restart point集合进行二分搜索快速找到key所在的restart point,然后依次遍历key,直到大于等于key为止。
Status Table::InternalGet(const ReadOptions& options, const Slice& k, void* arg,
void (*handle_result)(void*, const Slice&,
const Slice&)) {
Status s;
Iterator* iiter = rep_->index_block->NewIterator(rep_->options.comparator);
iiter->Seek(k);
if (iiter->Valid()) {
Slice handle_value = iiter->value();
FilterBlockReader* filter = rep_->filter;
BlockHandle handle;
if (filter != nullptr && handle.DecodeFrom(&handle_value).ok() &&
!filter->KeyMayMatch(handle.offset(), k)) {
// Not found
} else {
Iterator* block_iter = BlockReader(this, options, iiter->value());
block_iter->Seek(k);
if (block_iter->Valid()) {
(*handle_result)(arg, block_iter->key(), block_iter->value());
}
s = block_iter->status();
delete block_iter;
}
}
if (s.ok()) {
s = iiter->status();
}
delete iiter;
return s;
}
void Seek(const Slice& target) override {
// Binary search in restart array to find the last restart point
// with a key < target
uint32_t left = 0;
uint32_t right = num_restarts_ – 1;
while (left < right) {
uint32_t mid = (left + right + 1) / 2;
uint32_t region_offset = GetRestartPoint(mid);
uint32_t shared, non_shared, value_length;
const char* key_ptr =
DecodeEntry(data_ + region_offset, data_ + restarts_, &shared,
&non_shared, &value_length);
if (key_ptr == nullptr || (shared != 0)) {
CorruptionError();
return;
}
Slice mid_key(key_ptr, non_shared);
if (Compare(mid_key, target) < 0) {
// Key at “mid” is smaller than “target”. Therefore all
// blocks before “mid” are uninteresting.
left = mid;
} else {
// Key at “mid” is >= “target”. Therefore all blocks at or
// after “mid” are uninteresting.
right = mid – 1;
}
}
// Linear search (within restart block) for first key >= target
SeekToRestartPoint(left);
while (true) {
if (!ParseNextKey()) {
return;
}
if (Compare(key_, target) >= 0) {
return;
}
}
}
sstable文件的生成与合并
immutable memtable内存dump到sstable文件,上面已经介绍了的sstable文件的生成过程。之后为该新生成的sstable文件选择一个合适的level,放入version的文件清单中。
int Version::PickLevelForMemTableOutput(const Slice& smallest_user_key,
const Slice& largest_user_key) {
int level = 0;
if (!OverlapInLevel(0, &smallest_user_key, &largest_user_key)) {
// Push to next level if there is no overlap in next level,
// and the #bytes overlapping in the level after that are limited.
InternalKey start(smallest_user_key, kMaxSequenceNumber, kValueTypeForSeek);
InternalKey limit(largest_user_key, 0, static_cast<ValueType>(0));
std::vector<FileMetaData*> overlaps;
while (level < config::kMaxMemCompactLevel) {
if (OverlapInLevel(level + 1, &smallest_user_key, &largest_user_key)) {
break;
}
if (level + 2 < config::kNumLevels) {
// Check that file does not overlap too many grandparent bytes.
GetOverlappingInputs(level + 2, &start, &limit, &overlaps);
const int64_t sum = TotalFileSize(overlaps);
if (sum > MaxGrandParentOverlapBytes(vset_->options_)) {
break;
}
}
level++;
}
}
return level;
}
leveldb读取流程触发的compaction 在查找key的过程中,可能会搜索多个sstable文件,对于未查找到key的第一个sstable文件标记一次查找,如果sstable文件的allowed_seeks为0了,则需要对该sstable文件进行合并处理。
bool Version::UpdateStats(const GetStats& stats) {
FileMetaData* f = stats.seek_file;
if (f != nullptr) {
f->allowed_seeks—;
if (f->allowed_seeks <= 0 && file_to_compact_ == nullptr) {
file_to_compact_ = f;
file_to_compact_level_ = stats.seek_file_level;
return true;
}
}
return false;
}
每次重启恢复version或者生成新version的时候,遍历所有的level层,选取一个最需要compaction的level和sstable文件进行合并。
void VersionSet::Finalize(Version* v) {
// Precomputed best level for next compaction
int best_level = –1;
double best_score = –1;
for (int level = 0; level < config::kNumLevels – 1; level++) {
double score;
if (level == 0) {
// We treat level-0 specially by bounding the number of files
// instead of number of bytes for two reasons:
//
// (1) With larger write-buffer sizes, it is nice not to do too
// many level-0 compactions.
//
// (2) The files in level-0 are merged on every read and
// therefore we wish to avoid too many files when the individual
// file size is small (perhaps because of a small write-buffer
// setting, or very high compression ratios, or lots of
// overwrites/deletions).
score = v->files_[level].size() /
static_cast<double>(config::kL0_CompactionTrigger);
} else {
// Compute the ratio of current size to size limit.
const uint64_t level_bytes = TotalFileSize(v->files_[level]);
score =
static_cast<double>(level_bytes) / MaxBytesForLevel(options_, level);
}
if (score > best_score) {
best_level = level;
best_score = score;
}
}
v->compaction_level_ = best_level;
v->compaction_score_ = best_score;
}
sstable文件合并的过程
// Each compaction reads inputs from “level_” and “level_+1”
std::vector<FileMetaData*> inputs_[2]; // The two sets of inputs
// State used to check for number of overlapping grandparent files
// (parent == level_ + 1, grandparent == level_ + 2)
std::vector<FileMetaData*> grandparents_;
如果compaction_score_>=1,则从compaction_level_中选择包含大于该level层上次合并中处理过的最大key的sstable文件作为inputs[0],如果没有找到则选择第一个文件,因为此时说明该level层所有sstable文件都经过一次循环了,可以开始新一轮的循环。如果file_to_compact_不为空,则说明有sstable文件的allowed_seeks为0了,此时选择file_to_compact_level_层的file_to_compact_文件作为上层文件。对于0层文件,由于0层sstable文件间key可能会重合,需要把与所选sstable文件的key有范围重叠的sstable文件也加入进来一起作为inputs[0]。对于inputs[1],会从level+1中选择所有与上层文件有key范围重合的sstable文件。确定好inputs[0]和inputs[1]后,再进行一次调整。
// See if we can grow the number of inputs in “level” without
// changing the number of “level+1” files we pick up.
if (!c->inputs_[1].empty()) {
std::vector<FileMetaData*> expanded0;
current_->GetOverlappingInputs(level, &all_start, &all_limit, &expanded0);
AddBoundaryInputs(icmp_, current_->files_[level], &expanded0);
const int64_t inputs0_size = TotalFileSize(c->inputs_[0]);
const int64_t inputs1_size = TotalFileSize(c->inputs_[1]);
const int64_t expanded0_size = TotalFileSize(expanded0);
if (expanded0.size() > c->inputs_[0].size() &&
inputs1_size + expanded0_size <
ExpandedCompactionByteSizeLimit(options_)) {
InternalKey new_start, new_limit;
GetRange(expanded0, &new_start, &new_limit);
std::vector<FileMetaData*> expanded1;
current_->GetOverlappingInputs(level + 1, &new_start, &new_limit,
&expanded1);
if (expanded1.size() == c->inputs_[1].size()) {
Log(options_->info_log,
“Expanding@%d %d+%d (%ld+%ld bytes) to %d+%d (%ld+%ld bytes)\n“,
level, int(c->inputs_[0].size()), int(c->inputs_[1].size()),
long(inputs0_size), long(inputs1_size), int(expanded0.size()),
int(expanded1.size()), long(expanded0_size), long(inputs1_size));
smallest = new_start;
largest = new_limit;
c->inputs_[0] = expanded0;
c->inputs_[1] = expanded1;
GetRange2(c->inputs_[0], c->inputs_[1], &all_start, &all_limit);
}
}
}
// Compute the set of grandparent files that overlap this compaction
// (parent == level+1; grandparent == level+2)
if (level + 2 < config::kNumLevels) {
current_->GetOverlappingInputs(level + 2, &all_start, &all_limit,
&c->grandparents_);
}
如果input[0]只有一个sstable,input[1]没有sstable,并且level+2中与input有key重合的所有文件size小于MaxGrandParentOverlapBytes(vset->options_),则可以直接将input[0]的sstable文件挪到level+1层。
c->edit()->DeleteFile(c->level(), f->number);
c->edit()->AddFile(c->level() + 1, f->number, f->file_size, f->smallest, f->largest);
构造input[0]、input[1]的迭代器MergingIterator,遍历所有的key,生成新的sstable文件,放入level+1层中,生成新的version,这里一旦新sstable文件与level+2层的sstable有key重合的filesize之和超过MaxGrandParentOverlapBytes(vset->options_)或者新sstable文件大小达到MaxFileSizeForLevel(options, level)则结束当前新sstable的写入,需要再另建一个新sstable去满足后续的写入。遍历期间会丢弃一些key,比如:多次出现的user_key,只需要保留到第一个sequence小于smallest_snapshot的key为止。对于kTypeDeletion类型的key,如果其sequence <= smallest_snapshot,并且level+2层之后没有该user_key,则可以丢弃。
版本管理与版本恢复
Version:代表了某一时刻的数据库版本信息,版本信息的主要内容是当前各个Level层sstable文件的元信息。VersionSet:维护了一份Version列表,包含当前Alive的所有Version信息,列表中第一个代表数据库的当前版本。VersionEdit:表示Version之间的变化,相当于delta 增量,表示某次版本变更中增加了哪些文件以及删除了哪些文件。Version0+VersionEdit–>Version1。VersionEdit会保存到Manifest文件中,当做数据恢复时就会从Manifest文件中读出来重建版本数据。 leveldb启动后,会通过current文件得到Manifest文件,然后依次读取文件中的VersionEdit信息来恢复到之前的版本状态。每生成一次新version都会往Manifest文件中写入VersionEdit信息,第一次写入的时候会新创建一个Manifest文件(目前leveldb的options_->reuse_logs默认是false,每次启动后,之前的Manifest文件都不会被重复利用),然后将当前的version编码成VersionEdit写入Manifest文件当做进程启动后的版本信息快照,同时生成1个current文件,文件内容是Manifest文件名。后续的写入,只要把每一次的增量变化VersionEdit写入Manifest文件即可。
std::string new_manifest_file;
Status s;
if (descriptor_log_ == nullptr) {
// first call to LogAndApply (when opening the database).
assert(descriptor_file_ == nullptr);
new_manifest_file = DescriptorFileName(dbname_, manifest_file_number_);
edit->SetNextFile(next_file_number_);
s = env_->NewWritableFile(new_manifest_file, &descriptor_file_);
if (s.ok()) {
descriptor_log_ = new log::Writer(descriptor_file_);
s = WriteSnapshot(descriptor_log_);
}
}
// Unlock during expensive MANIFEST log write
{
mu->Unlock();
// Write new record to MANIFEST log
if (s.ok()) {
std::string record;
edit->EncodeTo(&record);
s = descriptor_log_->AddRecord(record);
if (s.ok()) {
s = descriptor_file_->Sync();
}
if (!s.ok()) {
Log(options_->info_log, “MANIFEST write: %s\n“, s.ToString().c_str());
}
}
// If we just created a new descriptor file, install it by writing a
// new CURRENT file that points to it.
if (s.ok() && !new_manifest_file.empty()) {
s = SetCurrentFile(env_, dbname_, manifest_file_number_);
}
mu->Lock();
}
leveldb的memtable的恢复是通过读取log文件,从当前版本中获取当前的log文件编号min_log,恢复的时候只需要读取文件编号>=min_log的日志文件,然后从log文件中依次读取key-value键值对写入memtable。
for (size_t i = 0; i < logs.size(); i++) {
s = RecoverLogFile(logs[i], (i == logs.size() – 1), save_manifest, edit,
&max_sequence);
if (!s.ok()) {
return s;
}
}
LruCache机制
LevelDB的Cache有table cache和block cache,其底层实现都是分成了16个shard的LruCache。table cache缓存的是sstable的索引数据,类似于文件系统中对inode的缓存;block cache是缓存的block数据,block是sstable文件内组织数据的单位,类似于Linux中的page cache。leveldb中,table cache默认大小是1000,注意此处缓存的是1000个sstable文件的索引信息,而不是1000个字节。block cache默认是缓存8M字节的block数据。LruCache的底层实现有2个双向list,一个hash_map。lru_这个list存储的是缓存在hash_map中但没有被外部调用者引用的数据;in_use_这个list存储的是缓存在hash_map中并且至少被一个外部调用者引用的数据(refs >= 2),因此缓存数据只会存在于lru_和in_use_其中一个list中。hash_map的作用是加速数据查找。
// Dummy head of LRU list.
// lru.prev is newest entry, lru.next is oldest entry.
// Entries have refs==1 and in_cache==true.
LRUHandle lru_ GUARDED_BY(mutex_);
// Dummy head of in-use list.
// Entries are in use by clients, and have refs >= 2 and in_cache==true.
LRUHandle in_use_ GUARDED_BY(mutex_);
HandleTable table_ GUARDED_BY(mutex_);
参考链接
https://blog.csdn.net/Swartz2015/article/details/66474681 http://taobaofed.org/blog/2017/07/05/leveldb-analysis/ https://leveldb-handbook.readthedocs.io/zh/latest/journal.html https://leveldb-handbook.readthedocs.io/zh/latest/rwopt.html https://www.jianshu.com/p/27e48eae656d