作为一个程序员,经常需要读一些开源项目的源码。同时呢,读源码对我们也有很多好处:
1.提升自己
阅读优秀的代码,第一可以提升我们自身的编码水平,第二可以开拓我们写代码的思路,第三还可能让我们拿到大厂 offer。无论那种情况,优秀的代码就是提升我们开发水平的资粮,而把这些优秀的代码读懂、读透并不很容易。
2.修复 Bug
有些时候,我们用的一些开源组件,出现了一些预想不到的问题。而这时候,也没有前人经验可借鉴,也没有文档可供参考,只能靠自己修复。阅读代码,理解项目,才能顺利修复问题。如果阅读代码水平不够,修复 Bug 这事儿就成了个棘手的事儿,影响咱们的工作。
3.增加新功能
在工作中,我们会遇到翻遍开源库也没有特别合适的组件的情况。这就只能对现有的组件进行改造,而这种改造的前置条件就是去理解开源组件。这时候,我们只能去阅读代码。
读源码好处很多,但是,读源码本身不是件简单的事。
相反,这是件非常困难的事情。一般来说,读代码比较困难的情况体现在: – 代码读起来太枯燥,读了一会儿就犯困、犯糊涂; – 代码读了很长时间,结果发现不知道得到了什么,花了时间却什么也没学到,读了个寂寞; – 一个开源组件,读代码就花了好几天,就这也才弄懂了一两个文件里的代码,结果耽误了正常工作。
自我工作以来,长期和各种开源组件打交道,也被迫读了许多的代码。在经历了以上种种困难之后,花费了好几年的时间,我才算总结了一套自己的打法,才算能真正的去快速的读懂、读透许多开源组件。
恰好也有许多读者朋友问起我该如何读代码,所以,我决定把我总结的一些套路写出来,望能给大家一些帮助,能更快的提升自己。
那我们来看看我个人读代码的一些办法。
一、纵览全局
阅读代码之前,首先我们要用上帝视角去看源码,用上帝视角目的在于去了解这个组件的全貌。
全貌包括:
1. 开源项目的主要用途
我们要知道项目主要是用来干嘛的,因为这是项目的终极目标。
所有开源项目的源码本身都是为了这个终极目标才写出来的。
例如,对于 logback 而言,它的用途就是打日志。而它所有的代码无论多复杂,终极目标就是要让 logback 能健壮高效的打印出日志来。
2. 项目的架构
了解项目架构的价值在于,能了解系统的层次结构,就能理出项目的核心脉络。有了核心脉络,我们就能把有限的时间用在阅读最有价值的代码上。
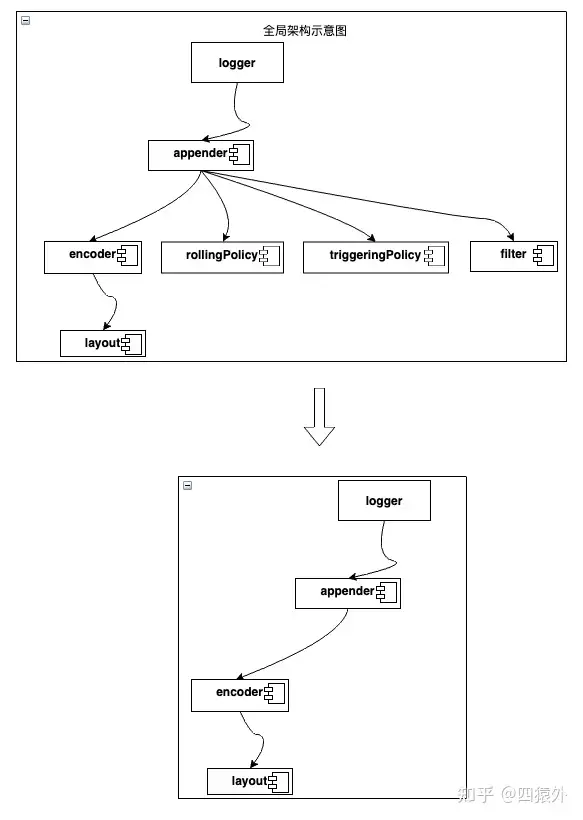
如果项目的官方文档有架构图,那么就从官方的架构图去了解项目的整体架构。如果文档中没有架构图,就去搜一下有没有民间大神画出来,如果还没有,可以根据官方文档的描述,自己画出来架构图。
以 logback 为例,由于官方没有提供架构图,我根据文档大概画了一个架构图。
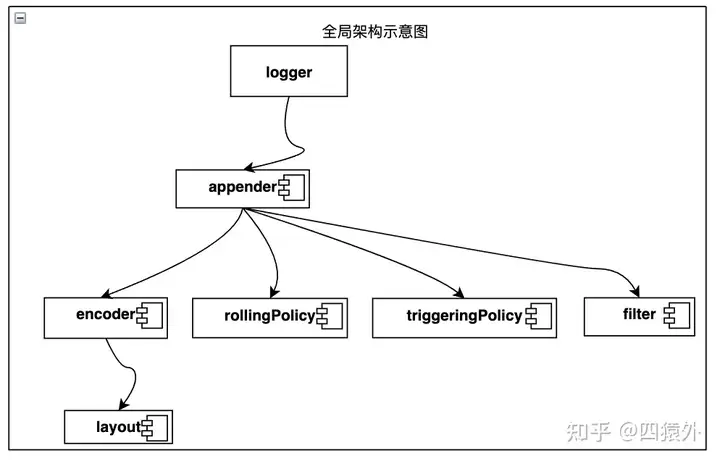
二、把玩无厌
摸清楚了系统的核心脉络,我们还需要把项目运行起来。
运行项目有两个目的:
1. 知道这个项目运行前有哪些必须的前置条件
还是回到 logback 的例子上。
当我们能成功运行 logback 后,其必然存在了一个 logback.xml 文件,否则无法运行。
这个 logback.xml 文件其实对于我们看源码非常重要,它点出了 logback 需要的关键元素。
并且,如果读源码遇到了困惑,明白了这个配置文件,就能有效帮助我们跨过障碍。后面谈到如何具体的读源码时再细说。
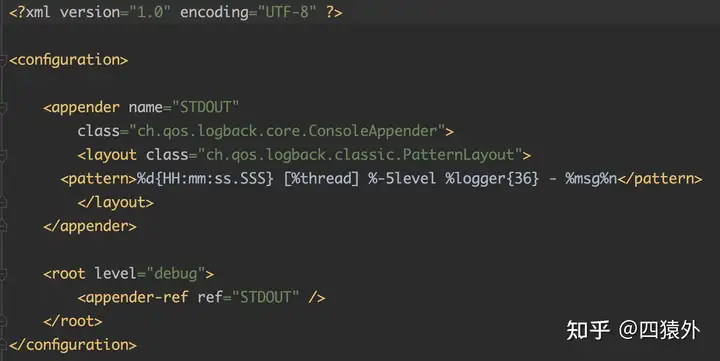
上面是一个基本的 logback 配置,里面列出了 logback 运行需要的关键组件。
2. 读代码出现疑惑,可以通过调试去解开自己的困惑
我们读的开源项目往往都很复杂。最典型的有三种情况:
方法变量不知其意逻辑跳转绕来绕去封装对象层次太深而以上的情况,都只能通过代码调试才能解决。
三、抽丝剥茧
全貌、核心脉络知道了,项目运行起来了,你心里说,这下我要读代码了吧?
错,你还差一步,那就是细化目标。
我前面说过,我们读源代码的目的有三类: 1. 提升自己 2. 修复 bug 3. 添加新功能
但是,这些目的过于模糊了。提升自己,那读哪些代码能提升自己?修复 bug,读哪些代码能修复 bug?添加新功能,读哪些代码能把新功能加上?
所以,得把这些有效的代码选出来。如何选呢?
当我们从事开发工作,听得最多的一件事就是把问题分解:把大问题分解成小问题,分而克之。
选择并阅读有效代码也是一样的。
对于过大的代码量,过多的功能,我们紧要的一件事儿就是把比较模糊的目标分解成能具体落地的精准的小目标。这些小目标对应到项目中,其实就是项目的一个一个的业务流程。
比如我们想给 logback 添加个新功能,能让公司的日志打印出统一的固定格式。看看我们如何做:
1. 纵向分解
纵向分解就是在我们已知的架构图上分解出来一条条纵向的业务流程。
由于我们想统一公司的日志格式,那肯定就需要在打印到文件前,把日志内容格式化好。所以,业务流程就应该选择从应用日志调用 logback 打印日志开始,一直到日志内容输出到目标文件结束的业务流程。
2. 横向扩展
横向扩展定下了我们如何组合业务流程,从而可以完整的达成咱们开始定下的大目标。
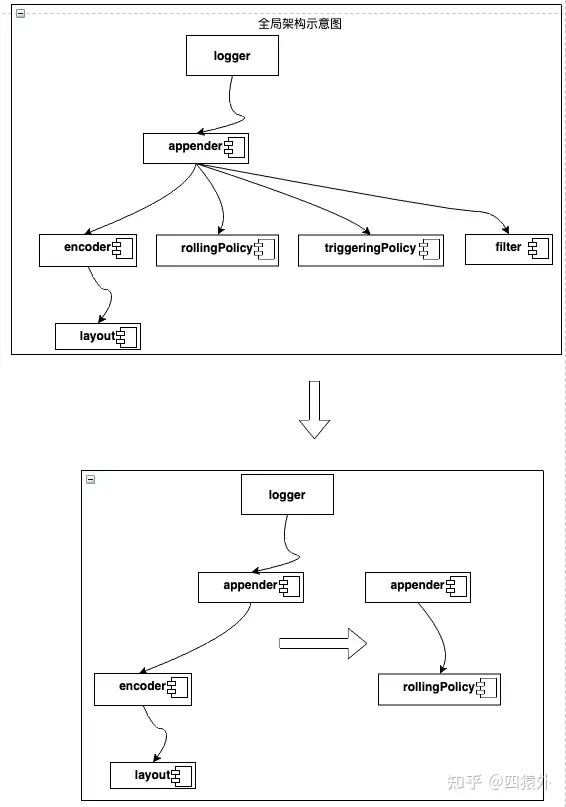
比如,这里就可以定下在看完 logback 打印日志的流程后,再去看看 logback 的日志是如何切换的。
四、腾龙入海
好了,现在我们终于要开始看代码了。
但是看代码也是要讲究技巧的,并不是上来就瞎翻瞎看。
1. 请将我心照明月
首先,我们曾经细化了目标,抽出了一条完整的业务流程。有此之后,我们就可以把业务流程和代码逻辑给映射起来。
看看logback的情况:
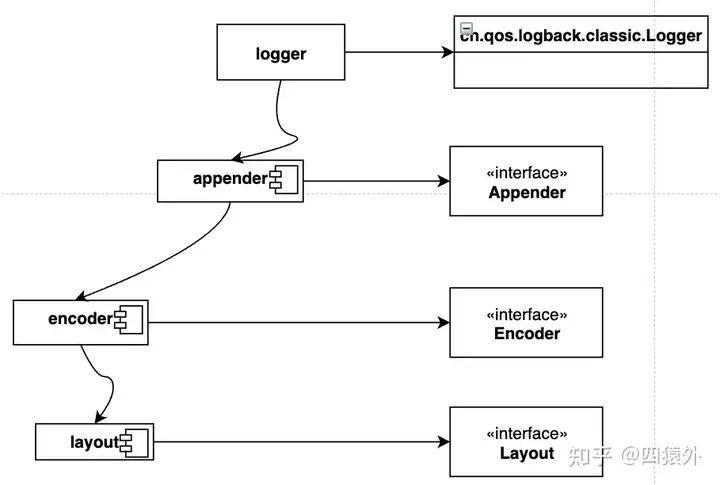
2. 一入侯门深似海
业务关系映射完毕,我们就能开始读代码了。在读代码的时候,我们还需要掌握几个技巧:
技巧一:代码一定跳着看
有件事我们得明白,不是所有的代码都值得仔细看的。我们最优先的,就是看正向流程的,核心的代码,其余代码皆可以跳过。
可以跳过的代码大概有:
判断异常输入的代码——这类代码对咱们理解系统意义不大,等到以后想提升自己编码能力的时候,可以回头专门找一些优秀的代码集中学。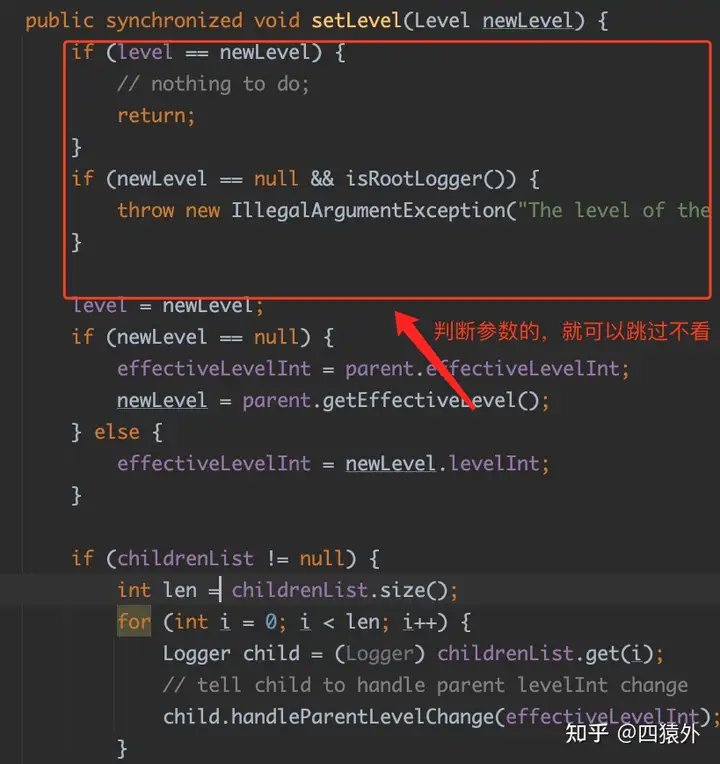
技巧二:调用关系需确定
在看代码的时候,有一些方式会严重我们读代码。
如果你一旦读代码发现你找不到后续流程了,就得考虑考虑,作者是不是用了非顺序调用方式去调用后续方法或者对象。
一般来说,开发人员常用以下几种方式做非顺序调用: – 通过中间件继续后续流程,比如 MQ – 通过异步方式继续后续流程,比如 Future 模式、Promises 模式 – 通过回调方式继续后续流程 – 通过代理委托方式继续后续流程,比如动态代理 – 通过依赖注入方式继续后续流程,比如 Spring 的 autowired 注解
这些非顺序调用会严重影响我们阅读代码。而对于这几种情况,解决的办法大概有两种: – 直接猜——其实后续流程我们在做业务流程映射到实际的代码对象的时候已经大概知道了,如果是接口,我们看看实现类不多,就可以大概挨个看下,一般都能猜着是哪个。 – 运行起来调试下——这种办法是很普遍的,对任何不确定的任何事情,其实都可以用这个方式。
技巧三:超难算法放最后
对于某些开源项目,它会采用很多经典的算法。很经典,当然也很难。
但是,对于理解整体项目来说,这些算法会严重阻碍我们的进程。我建议这些算法,可以先记下来位置。在后续集中就着算法资料,慢慢理解。
上面是 logback 日志文件分割的算法,在理解业务流程时,不建议马上去理解算法,可以放在后面自己另外定个目标理解。
以上就是我多年来一直沿用的代码阅读套路。
总结下
首先,阅读代码之前,我们应该对项目的全局做一个了解。我们可以从官方文档、民间博客之类的去加快了解全局的速度。最好能参考一些架构图、时序图,如果没有现成的图,最好能自己画出一些来。
然后,我们把项目运行起来,运行起来才能有助于我们后续的调试,才能有助于我们快速的理解那些难懂的代码段。
再后,把我们的目标细化成一条条业务流程。没有这些业务流程,我们一下子去读大片大片的代码,第一没有清晰的脉络,第二也没有可及的任务目标……结果就是一片混乱。
最后,才开始去真正的读代码。而读代码,我们应该有技巧的读,要知道如何跳过某些代码,要知道如何技巧的找到后续调用流程,还要知道如何把一些困难去集中攻克。
正是通过这种套路,我读代码不仅速度快,而且理解够深入。
另外,代码读的多了,还有一大好处:当我在设计项目架构的时候,写一套框架的时候,不自觉就会浮现出类似的项目或者代码块来。
总之,读代码令我获益颇多,这也是我职业生涯比较顺利的重要原因之一,也在此希望帮助到后来者。
如果你觉得这篇文章对你有帮助,请帮忙点个赞,一个小小的点赞也算是对我原创的支持。