介绍
我喜欢智慧城市的理念。自动智能能源系统、电网、一键接入端口的想法等等。这是一个令人着迷的概念!老实说,这是一个数据科学家的梦想,我很高兴世界上很多城市都在朝着更智能的方向发展。
智能城市的核心组成部分之一是自动交通管理。这不禁让我思考——我能用我的数据科学知识来建立一个车辆检测模型,在智能交通管理中发挥作用吗?
想想看,如果你能在红绿灯摄像头中集成车辆检测系统,你可以轻松地同时跟踪许多有用的东西:
白天交通路口有多少辆车?什么时候交通堵塞?什么样的车辆(重型车辆、汽车等)正在通过交叉路口?有没有办法优化交通,并通过不同的街道进行分配?还有很多例子就不一一列举。应用程序是无止境的!
我们人类可以很容易地在一瞬间从复杂的场景中检测和识别出物体。然而,将这种思维过程转化为机器的思维,需要我们学习使用计算机视觉算法进行目标检测。
因此在本文中,我们将建立一个自动车辆检测器和计数器模型。以下视频是你可以期待的体验:
https://youtu.be/C_iZ2yivskE
注意:还不懂深度学习和计算机视觉的新概念?以下是两门热门课程,可开启你的深度学习之旅:
深度学习基础(https://courses.analyticsvidhya.com/courses/fundamentals-of-deep-learning?utm_source=blog&utm_medium=vehicle-detection-opencv-python)利用深度学习的计算机视觉(https://courses.analyticsvidhya.com/courses/computer-vision-using-deep-learning-version2?utm_source=blog&utm_medium=vehicle-detection-opencv-python)目录
视频中运动目标检测的思想视频中目标检测的真实世界用例视频目标检测的基本概念 帧差分 图像阈值 检测轮廓 图像膨胀利用OpenCV构建车辆检测系统视频中运动目标检测的思想
目标检测是计算机视觉中一个引人入胜的领域。当我们处理视频数据时,它达到了一个全新的水平,复杂性上升了一个等级,但也有回报!
我们可以使用目标检测算法来执行超级有用的高价值任务,如监视、交通管理、打击犯罪等。下面的GIF图演示了这个想法:
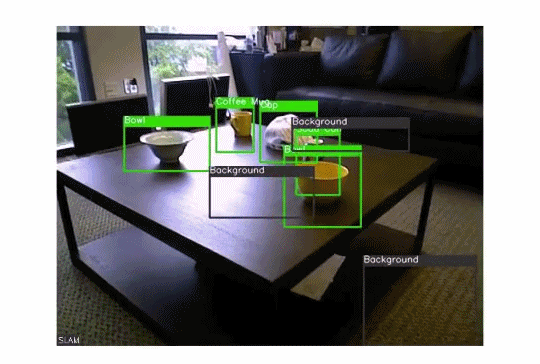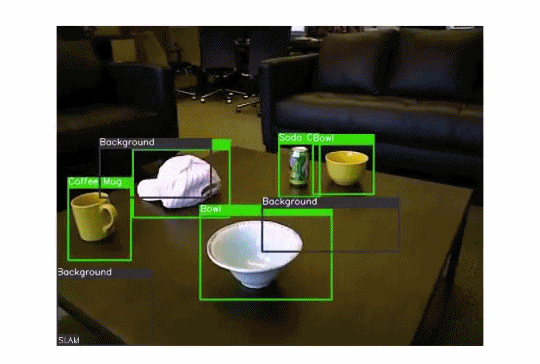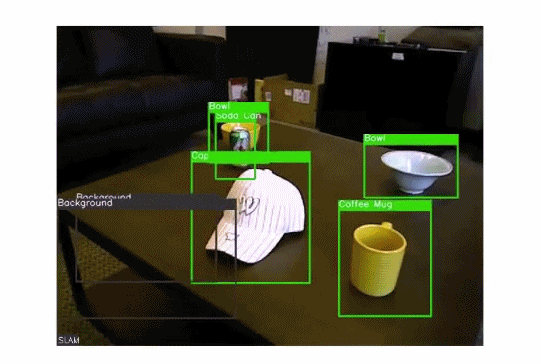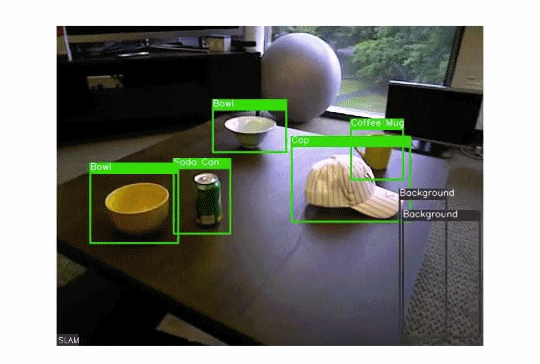
在目标检测中,我们可以执行许多子任务,例如计算目标数量、查找目标的相对大小或查找目标之间的相对距离。这些子任务都很重要,因为它们有助于解决一些最棘手的现实问题。
如果你希望从头开始学习目标检测,我建议你使用以下教程:
逐步介绍基本的目标检测算法(https://www.analyticsvidhya.com/blog/2018/10/a-step-by-step-introduction-to-the-basic-object-detection-algorithms-part-1/?utm_source=blog&utm_medium=vehicle-detection-opencv-python)利用SlimYOLOv3进行实时目标检测(https://www.analyticsvidhya.com/blog/2019/08/introduction-slimyolov3-real-time-object-detection/?utm_source=blog&utm_medium=vehicle-detection-opencv-python)其他目标检测物品和资源(https://www.analyticsvidhya.com/blog/tag/object-detection/?utm_source=blog&utm_medium=vehicle-detection-opencv-python)让我们看看一些令人兴奋的现实世界中的目标检测用例。
视频中目标检测的真实世界用例
如今,视频目标检测正被广泛应用于各个行业。使用案例从视频监控到体育广播,再到机器人导航。
好消息是,在未来的视频目标检测和跟踪用例中,可能性是无穷的。这里我列出了一些有趣的应用程序:
人群计数(https://www.analyticsvidhya.com/blog/2019/02/building-crowd-counting-model-python/)车牌检测与识别运动中的球跟踪(https://www.analyticsvidhya.com/blog/2020/03/ball-tracking-cricket-computer-vision/)机器人学交通管理(我们将在本文中看到这个想法)视频目标检测的基本概念
在开始构建视频检测系统之前,你应该知道一些关键概念。一旦你熟悉了这些基本概念,就可以为你选择的任何用例构建自己的检测系统。
那么,你希望如何检测视频中的移动目标?
我们的目标是捕捉运动物体的坐标并在视频中突出显示该物体。请考虑下面视频中的这一帧:

我们希望我们的模型能够检测视频中的运动目标,如上图所示。检测到移动的汽车,并在汽车周围创建一个边界框。
解决这个问题有多种方法。你可以为目标检测训练一个深度学习模型,也可以选择一个预先训练好的模型并根据你的数据对其进行微调。然而,这些方法都是有监督的学习方法,需要标记数据来训练目标检测模型。
在本文中,我们将重点讨论视频中无监督的目标检测方法,即不使用任何标记数据的目标检测。我们将使用帧差分技术。让我们了解它是如何工作的!
帧差分
视频是一组按正确顺序堆叠在一起的帧。所以,当我们看到一个物体在视频中移动时,这意味着这个物体在每一个连续的帧上都处于不同的位置。

如果我们假设除了该目标之外,在一对连续的帧中没有其他物体移动,那么第一帧与第二帧的像素差将突出显示移动目标的像素。现在,我们得到了移动物体的像素和坐标。这就是帧差分法的工作原理。
举个例子。考虑视频中的以下两个帧:

你能看出这两帧的区别吗?
握笔的手的位置从第1帧变为第2帧。其余的物体根本没有移动。所以,正如我前面提到的,为了定位移动目标,我们将执行帧差分。结果如下:

你可以看到高亮或白色区域,这是手最初出现的地方。除此之外,记事本的边缘也会突出显示一点。这可能是由于手的移动改变了光照。建议不要对静止物体进行不必要的检测。因此,我们需要对帧执行某些图像预处理步骤。
图像阈值
在这种方法中,灰度图像的像素值根据阈值被指定为表示黑白颜色的两个值之一。因此,如果一个像素的值大于一个阈值,它被赋予一个值,否则它被赋予另一个值。
在本例中,我们将对上一步骤中帧差分的输出图像应用图像阈值:

你可以看到,不需要的高亮区域的大部分已经消失了。高亮显示的“记事本”边缘不再可见。合成的图像也可以称为二值图像,因为其中只有两种颜色。在下一个步骤中,我们将看到如何捕获这些高亮区域。
检测轮廓
轮廓用于识别图像中具有相同颜色或强度的区域的形状。轮廓就是目标区域周围的边界。因此,如果我们在阈值步骤后对图像应用轮廓检测,我们将得到以下结果:

白色区域被浅灰色的边界所包围,这些边界就是轮廓。我们很容易得到这些轮廓的坐标。这意味着我们可以得到高亮区域的位置。
请注意,有多个高亮显示区域,每个区域由轮廓包围。在我们的例子中,具有最大面积的轮廓是我们期望的区域。因此,轮廓最好尽可能少。
在上图中,仍然有一些不必要的白色区域碎片。还有改进的余地。我们的想法是合并附近的白色区域以获得更少的轮廓,为此,我们可以使用另一种称为图像膨胀的技术。
图像膨胀
这是对图像的卷积操作,其中核心(矩阵)传递到整个图像上。为了给你直觉,右边的图像是左边图像的放大版本:

所以,让我们对我们的图像进行图像膨胀,然后我们将再次找到轮廓:

事实证明,许多支离破碎的区域已经相互融合。现在我们可以再次在这张图片中找到轮廓:

在这里,我们只有四个候选轮廓,从中我们可以选择一个有最大面积的轮廓。也可以在原始帧上绘制这些轮廓,以查看轮廓围绕移动目标的情况:

用OpenCV和Python构建车辆检测系统
我们准备建立我们的车辆检测系统!在这个实现中,我们将大量使用计算机视觉库OpenCV(4.0.0版)(https://www.analyticsvidhya.com/blog/2019/03/opencv-functions-computer-vision-python/?utm_source=blog&utm_medium=vehicle-detection-opencv-python) 。我们先导入所需的库和模块。
导入库
import osimport reimport cv2 # opencv libraryimport numpy as npfrom os.path import isfile, joinimport matplotlib.pyplot as plt导入视频帧
请从此链接下载原始视频的帧。
https://drive.google.com/file/d/1P0yiO5KlnU8dGgB_L68KB_hjIvUec55f/view
将框架保存在工作目录中名为“frames”的文件夹中。从该文件夹中,我们将导入帧并将其保存在列表中:
# get file names of the framescol_frames = os.listdir(frames/)# sort file namescol_frames.sort(key=lambda f: int(re.sub(\D, , f)))# empty list to store the framescol_images=[]for i in col_frames: # read the frames img = cv2.imread(frames/+i) # append the frames to the list col_images.append(img)数据探索
让我们显示两个连续的帧:
# plot 13th framei = 13for frame in [i, i+1]: plt.imshow(cv2.cvtColor(col_images[frame], cv2.COLOR_BGR2RGB)) plt.title(“frame: “+str(frame)) plt.show()

很难在这两个框架中找到区别,不是吗?如前所述,获取两个连续帧的像素值的差值将有助于我们观察移动目标。那么,让我们在上面两个帧上使用该技术:
# convert the frames to grayscalegrayA = cv2.cvtColor(col_images[i], cv2.COLOR_BGR2GRAY)grayB = cv2.cvtColor(col_images[i+1], cv2.COLOR_BGR2GRAY)# plot the image after frame differencingplt.imshow(cv2.absdiff(grayB, grayA), cmap = gray)plt.show()

现在我们可以清楚地看到第13帧和第14帧中的移动目标。其他没有移动的东西都被减去了。
图像预处理
让我们看看对上面的图像应用阈值后会发生什么:
diff_image = cv2.absdiff(grayB, grayA)# perform image thresholdingret, thresh = cv2.threshold(diff_image, 30, 255, cv2.THRESH_BINARY)# plot image after thresholdingplt.imshow(thresh, cmap = gray)plt.show()

现在,移动物体(车辆)看起来更像我们期望看到的那样了,大部分噪音(不希望出现的白色区域)都消失了。但是,突出显示的区域有点零碎。因此,我们可以对该图像应用图像膨胀:
# apply image dilationkernel = np.ones((3,3),np.uint8)dilated = cv2.dilate(thresh,kernel,iterations = 1)# plot dilated imageplt.imshow(dilated, cmap = gray)plt.show()

移动的物体有更多的实心高亮区域。希望帧中每个目标的轮廓数不超过3。
但是,我们不会使用整个框架来检测移动的车辆。我们将首先选择一个区域,如果车辆进入该区域,则仅检测到该区域。
那么,让我向你展示我们将会使用的区域:
# plot vehicle detection zoneplt.imshow(dilated)cv2.line(dilated, (0, 80),(256,80),(100, 0, 0))plt.show()

水平线y = 80以下的区域是我们的车辆检测区域。我们将只检测在这个区域发生的任何移动。你还可以创建自己的检测区。
现在让我们在上述帧的检测区域中找到轮廓:
# find contourscontours, hierarchy = cv2.findContours(thresh.copy(),cv2.RETR_TREE,cv2.CHAIN_APPROX_NONE)上面的代码查找整个图像中的所有轮廓,并将它们保存在变量”contours”中。由于我们只需要找到检测区域中存在的轮廓,我们将对发现的轮廓进行两次检查。
第一个检查是轮廓左上角的y坐标是否应大于等于80(我这里包括另一个检查,x坐标小于等于200)。另一个检查是轮廓的面积应该大于等于25。在cv2.courtoArea()函数的帮助下,你可以找到轮廓区域。
valid_cntrs = []for i,cntr in enumerate(contours): x,y,w,h = cv2.boundingRect(cntr) if (x <= 200) & (y >= 80) & (cv2.contourArea(cntr) >= 25): valid_cntrs.append(cntr)# count of discovered contours len(valid_cntrs)接下来,让我们绘制轮廓和原始帧:
dmy = col_images[13].copy()cv2.drawContours(dmy, valid_cntrs, -1, (127,200,0), 2)cv2.line(dmy, (0, 80),(256,80),(100, 255, 255))plt.imshow(dmy)plt.show()

太酷了!只有位于检测区域内的车辆轮廓可见。这就是我们在整个画面中检测车辆的方法
视频中的车辆检测
现在是时候对所有帧应用相同的图像变换和预处理操作,并找到所需的轮廓。重申一下,我们将遵循以下步骤:
对每对连续帧应用帧差分对上一步的输出图像应用图像阈值对上一步的输出图像进行图像放大在上一步的输出图像中查找轮廓检测区域出现的候选轮廓保存帧与最终轮廓# kernel for image dilationkernel = np.ones((4,4),np.uint8)# font stylefont = cv2.FONT_HERSHEY_SIMPLEX# directory to save the ouput framespathIn = “contour_frames_3/”for i in range(len(col_images)-1): # frame differencing grayA = cv2.cvtColor(col_images[i], cv2.COLOR_BGR2GRAY) grayB = cv2.cvtColor(col_images[i+1], cv2.COLOR_BGR2GRAY) diff_image = cv2.absdiff(grayB, grayA) # image thresholding ret, thresh = cv2.threshold(diff_image, 30, 255, cv2.THRESH_BINARY) # image dilation dilated = cv2.dilate(thresh,kernel,iterations = 1) # find contours contours, hierarchy = cv2.findContours(dilated.copy(), cv2.RETR_TREE,cv2.CHAIN_APPROX_NONE) # shortlist contours appearing in the detection zone valid_cntrs = [] for cntr in contours: x,y,w,h = cv2.boundingRect(cntr) if (x <= 200) & (y >= 80) & (cv2.contourArea(cntr) >= 25): if (y >= 90) & (cv2.contourArea(cntr) < 40): break valid_cntrs.append(cntr) # add contours to original frames dmy = col_images[i].copy() cv2.drawContours(dmy, valid_cntrs, -1, (127,200,0), 2) cv2.putText(dmy, “vehicles detected: ” + str(len(valid_cntrs)), (55, 15), font, 0.6, (0, 180, 0), 2) cv2.line(dmy, (0, 80),(256,80),(100, 255, 255)) cv2.imwrite(pathIn+str(i)+.png,dmy)准备视频
在这里,我们为所有帧中的所有移动车辆添加了轮廓。现在是时候堆叠帧并创建视频了:
# specify video namepathOut = vehicle_detection_v3.mp4# specify frames per secondfps = 14.0接下来,我们将阅读列表中的最后一帧:
frame_array = []files = [f for f in os.listdir(pathIn) if isfile(join(pathIn, f))]files.sort(key=lambda f: int(re.sub(\D, , f)))for i in range(len(files)): filename=pathIn + files[i] #read frames img = cv2.imread(filename) height, width, layers = img.shape size = (width,height) #inserting the frames into an image array frame_array.append(img)最后,我们将使用以下代码制作目标检测视频:
out = cv2.VideoWriter(pathOut,cv2.VideoWriter_fourcc(*DIVX), fps, size)for i in range(len(frame_array)): # writing to a image array out.write(frame_array[i])out.release()恭喜你学会了车辆目标检测!
尾注
在本教程中,我们学习了如何使用帧差分技术在视频中执行移动目标检测。我们还讨论了目标检测和图像处理的一些概念。然后用OpenCV建立了自己的运动目标检测系统。